Контейнеризация давным давно стала повсеместной и массовой практикой среди команд и администраторов IT систем. Docker используют и стартапы, и крупные компании, и небольшие команды разработчиков. Но вместе с удобством приходит и ответственность, ведь одной ошибки в конфигурации или сбоя диска достаточно, чтобы проект оказался под угрозой масштабного сбоя, а в иных случаях и полного уничтожения, так как данные могут быть потеряны, сервис стнет недоступным, а восстановление такого сбоя превращается в долгий и трудоемкий процесс.
Чтобы этого избежать, резервное копирование Docker-инфраструктуры должно быть не разовым действием, а частью общей архитектуры. В этой статье мы разберём ключевые элементы такой системы, выясним что именно нужно бэкапить, какие инструменты использовать, пробежимся по тому, какие ошибки допускают даже опытные инженеры и как построить стратегию, которая действительно работает.
Что действительно нужно бэкапить в Docker-инфраструктуре
Прежде чем настраивать какую-либо систему резервирования, важно понять, что именно в Docker-среде представляет ценность. Многие начинающие инженеры ошибочно пытаются «сделать бэкап контейнера». Но контейнер - это всего лишь исполняемый процесс, а процессы нет смысла сохранять. Сохранять необходимо данные и конфигурации, которые обеспечивают работоспособность проекта.
Ниже мы с вами разберём, какие именно элементы Docker-инфраструктуры подлежат резервированию и почему.
Что относится к критичным компонентам
Чтобы не тратить ресурсы на копирование ненужного, важно разделять данные по типам и целевой ценности. У каждого элемента инфраструктуры есть своя роль. Например база данных обеспечивает сохранение и целостность информации, медиафайлы - это пользовательский контент, а docker-compose.yml хранит архитектуру проекта.
Таблица ниже показывает, что действительно необходимо бэкапить, и какие инструменты лучше для этого подходят.
| Тип данных |
Нужно ли бэкапить |
Чем бэкапить |
Комментарий |
| PostgreSQL, MySQL, MongoDB |
Да |
pg_dump, mysqldump, mongodump |
Файлы тома нельзя копировать под нагрузкой |
| Загружаемые пользователями файлы |
Да |
tar, rsync |
Наиболее частая ценность проекта |
| Кеш (Redis, Memcached) |
Обычно нет |
snapshot или skip |
Кеш легко восстановить |
| Dockerfile, Compose, env |
Да |
Git |
Это «рецепт» сервиса |
| Docker-образы |
Иногда |
docker save |
Нужно, если нет Dockerfile или сборка ручная |
Почему тома должны быть центром любой стратегии резервирования
Тома Docker - это хранилище состояния. Контейнер можно уничтожить и пересоздать, но том в действительности является его реальным содержимым, так как именно на томах хранятся файлы базы данных, пользовательские файлы и другие важные артефакты. Поэтому любые обсуждения резервирования Docker-инфраструктуры так или иначе сводятся к работе с томами.
Для понимания, где физически находится том, можно использовать следующую команду:
docker volume inspect my_volume
А для его архивации - простую команду tar:
sudo tar -czf media_backup_$(date +%F).tar.gz /var/lib/docker/volumes/my_volume/_data
Тома - самое важное звено, которое нужно защищать, потому что именно они восстанавливают жизнеспособность проекта.
Реальный возможный сценарий сбоя
Для лучшего понимания представьте себе интернет-магазин, где база данных и медиа хранятся на Docker-томах. Если контейнер MySQL внезапно перестанет работать, то это мелочи. Можно очень быстро поднять новый контейнер с MySQL и указав ему место хранения данных - быстро восстановить работу сервиса.
Но если, по какой либо причине, том /var/lib/mysql станет нечитаемым, то это означает, что исчезнут заказы, транзакции, списки клиентов и все остальные данные, критически важные для проекта и бизнеса вцелом. Без него проект фактически потерян.
Однако, при наличии корректного бэкапа, восстановление тома и работы всего сервиса займет всего несколько минут.
Основные стратегии резервирования Docker-данных
Существует несколько подходов к резервированию, и каждый из них решает свои задачи. Универсального варианта не существует, так как то, что подходит для небольшого блога, может не подойти для высоконагруженной системы.
В этом разделе мы разберём основные стратегии, их преимущества, ограничения и варианты применения.
Обзор подходов резервирования и их применимость
Прежде чем переходить к каждому методу, стоит посмотреть на общую картину. Таблица ниже помогает понять, какой вариант подходит именно вашему проекту.
| Метод |
Скорость |
Надежность |
Сложность |
Где применяют |
| tar архивирование томов |
Средняя |
Средняя |
Низкая |
Недорогие VPS, средние проекты |
| Дамп баз данных |
Высокая |
Высокая |
Средняя |
Базы с высокой активностью |
| Снимки VM (snapshots) |
Очень высокая |
Высокая |
Средняя |
Proxmox, VMware, AWS |
| Облачные сервисы резервирования |
Высокая |
Высокая |
Средняя |
S3, Backblaze, Wasabi |
| Restic + rclone |
Высокая |
Очень высокая |
Средняя |
CI/CD, DevOps-проекты |
| GitOps |
Мгновенная |
Максимальная |
Низкая |
Все проекты |
Теперь давайте детальнее пробежимся по каждому пункту и проведём пдробный разбор каждого подхода в отдельности.
1. Резервирование томов через tar
Архивация томов - это один из самых простых способов сохранения данных. Он подходит для небольших проектов, где объём информации умеренный, а инфраструктура развёрнута на одном хосте.
Преимущество этого подхода в его универсальности, так как tar заработает везде, где есть доступ к файловой системе.
Пример:
docker volume inspect project_data sudo tar -czf data_$(date +%F).tar.gz /var/lib/docker/volumes/project_data/_data
Ограничения:
- не обеспечивает консистентность при активной записи в БД;
- медленно восстанавливается на больших объёмах;
- плохо подходит для высоконагруженных систем.
2. Экспорт данных баз через встроенные инструменты
Для серьёзных проектов предпочтительным методом является резервирование данных в виде дампов. Этот метод гарантирует согласованность состояния таблиц, даже если база работает под нагрузкой.
Для этого метода применяют специальные утилиты, которые предоставляет каждая СУБД, и их применение делает восстановление данных более предсказуемым, простым, а главное безопасным. Давайте посмотрим на примеры для разных СУБД.
PostgreSQL:
pg_dump -U user -F c -f backup.dump projectdb
MySQL:
mysqldump -u user -p database > dump.sql
MongoDB:
mongodump --out /backups/mongo_$(date +%F)
Такой подход подходит практически для всех производственных систем, в том числе при активном росте данных.
3. Снимки томов и виртуальных дисков (snapshots)
Виртуализация (Hyper-V, VMware, AWS EC2) позволяет делать моментальные снимки файловой системы. Это быстрый и надежный способ резервирования.
Основная идея snapshot-подхода заключается в «заморозке» состояния дисков в конкретный момент времени. Он эффективен при больших объёмах данных, когда обычный бэкап занимал бы часы.
Снимки хороши, если:
- проект работает на виртуальных машинах;
- данные активно изменяются;
- важна высокая скорость восстановления.
4. GitOps для конфигураций
Конфигурации - это основа предсказуемости. Без docker-compose.yml, Dockerfile и переменных окружения восстановление теряет структуру и превращается в угадывание параметров.
GitOps подход предполагает, что:
- все конфиги хранятся в Git;
- инфраструктура описана декларативно;
- сервер можно «воссоздать» из репозитория.
Это не заменяет бэкап данных, но дополняет его, делая восстановление быстрым и, что немаловажно, повторяемым.
Как построить грамотный план резервного копирования Docker
Эффективное резервирование - это не только выбор инструментов. Это процесс, который должен быть регулярным, документированным и автоматизированным. В этом разделе мы рассмотрим ключевые элементы рабочего плана, который можно использовать в любой Docker-инфраструктуре.
Определение критичных данных
Каждый проект имеет уникальную структуру ценности. Для e-commerce наиболее важны таблицы заказов, для медиа-сервисов - загруженные файлы, для SaaS - пользовательские данные. Определение критичных точек и есть основой плана резервирования.
Частота резервирования
Ритм копирования должен соответствовать ритму обновления данных:
- высоконагруженные базы - от нескольких раз в час;
- CMS, блоги - раз в сутки;
- крупные проекты - инкрементальные копии.
Правильно выбранная частота снижает нагрузку на сервер и обеспечивает актуальность копий.
Геораспределённость копий
Хранить резервные файлы на том же сервере, где работающие контейнеры - это прямой путь к потере данных.
Необходимо хранить копии на сервере в другом дата-центре, на S3, NAS или выделенном VPS.
Тестирование восстановления
Любой бэкап обязан быть проверен. Иначе он превращается лишь в иллюзию безопасности. Поэтому хотябы раз в месяц следует разворачивать тестовую среду и проверять, что восстановление проекта проходит полностью и без сбоев.
Типичная архитектура резервирования Docker-проекта
Рабочая архитектура обычно выглядит как цепочка компонентов. Это помогает обеспечить контроль на каждом этапе и автоматизировать процесс.
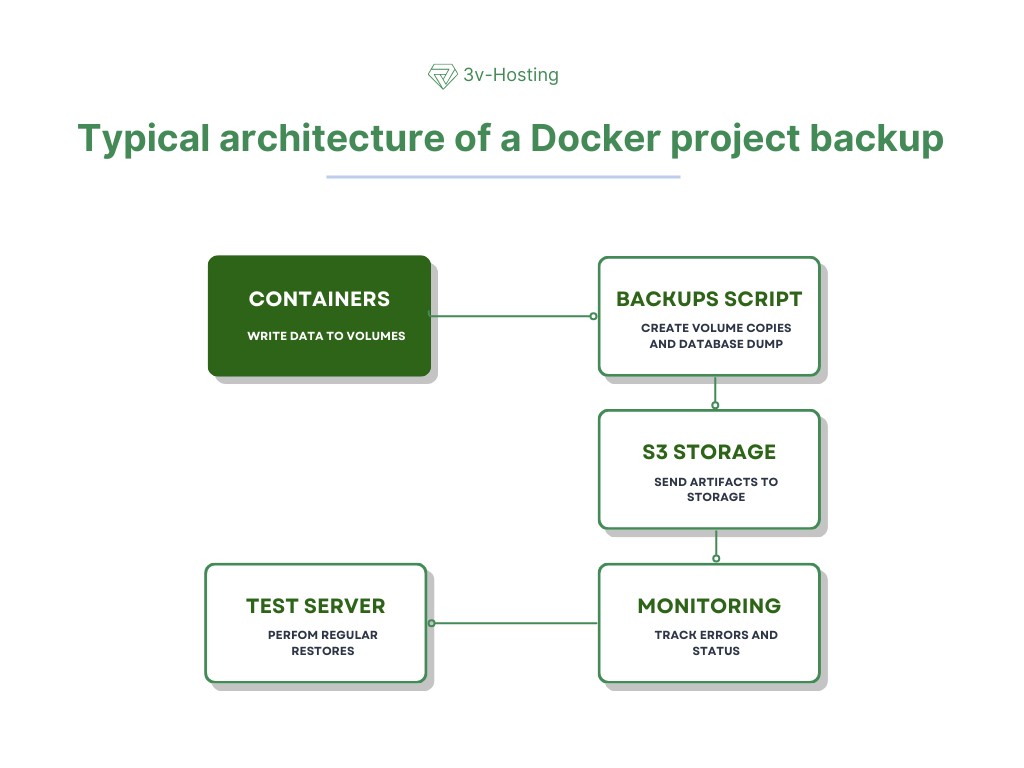
Контейнеры записывают данные в тома.
Каждый сервис работает внутри собственного контейнера, но все важные данные - базы, медиафайлы, кеши - сохраняются в выделенные тома. Это обеспечивает их независимость от контейнера и делает возможным последующее резервирование.
Скрипт создаёт копии томов и дампы баз.
По расписанию запускается автоматизированный скрипт или утилита, которая последовательно делает дампы баз данных и архивирует нужные тома. На этом этапе формируются полноценные бэкап-артефакты.
Артефакты отправляются в S3 или иной storage.
Полученные файлы загружаются в удалённое хранилище: объектное S3-хранилище, FTP, отдельный сервер или NAS. Это защищает данные от потери при сбое основного хоста.
На тестовом сервере регулярно проводится восстановление.
Чтобы убедиться, что бэкапы действительно рабочие, их периодически разворачивают на отдельном стенде. Это позволяет заранее обнаруживать проблемы, которые могли бы проявиться только в момент реального восстановления.
Мониторинг отслеживает ошибки и статус выполнения.
Все процессы резервирования логируются и отправляются в систему наблюдения (например, Prometheus или Grafana). Если копирование не выполнено, прервано или прошло с ошибками, команда получает оповещение и может оперативно отреагировать.
Ошибки, которые допускают даже опытные инженеры
Даже те, кто много лет работает с Docker, иногда совершают ошибки, которые приводят к потере данных. Отчасти это связано с тем, что Docker часто создаёт ложное ощущение безопасности.
К основным ошибкам относятся:
- хранение копий на том же диске;
- отсутствие дампов баз данных;
- игнорирование секретов;
- отсутствие логирования бэкапов;
- отсутствие версий резервных копий;
- хранение данных без шифрования.
Каждая из этих ошибок устраняется относительно просто, если включить резервирование в DevOps-процессы.
Инструменты для автоматизации резервирования
С увеличением количества контейнеров и данных в вашем проекте, ручное резервирование становится грамоздким и неудобным. Поэтому автоматизация должна быть обязательной частью вашей инфраструктуры. И удобными инструментами для автоматизации являются следующие инструменты:
Bash-скрипты
Для небольших Docker-хостов достаточно обычных bash-скриптов. Они позволяют полностью управлять процессом и легко адаптируются к любым требованиям.
Restic и rclone
Restic - это мощный инструмент, который поддерживает шифрование, дедупликацию и инкрементальные копии. В связке с rclone он отлично подходит для загрузки данных в S3 или Backblaze.
Velero
Хотя Velero ассоциируется с Kubernetes, его используют и для Docker-проектов, которым требуется сложная логика восстановления.
Docker Compose Backups (DCP)
Готовые утилиты, способные автоматически создавать архивы томов по расписанию.
Пример схемы резервирования небольшого проекта
Небольшие проекты (например, приложение + PostgreSQL + Nginx) могут использовать простую, но эффективную структуру бэкапов.
Каталоги:
/backups/
├── db/
├── media/
├── configs/
└── logs/
Простейший алгоритм:
- Выполнить pg_dump;
- Архивировать медиа том;
- Сохранить конфигурации в Git;
- Отправить файлы на S3;
- Очистить старые копии через logrotate.
Такой подход делает восстановление быстрым и повторяемым.
Многослойная стратегия резервирования
Надёжный подход предполагает наличие нескольких уровней резервного копирования, каждый из которых имеет свои цели.
| Уровень |
Частота |
Назначение |
| Горячие копии |
раз в 1–4 часа |
быстрое восстановление |
| Полные копии |
ежедневно |
защита от сбоев |
| Долгосрочные копии |
ежемесячно |
откат к старым состояниям |
Эта схема зачастую помогает защищаться от ошибок пользователей, критических багов, случайных удалений и аппаратных сбоев.
FAQ по резервному копированию Docker
Этот раздел отвечает на самые распространённые вопросы, которые чаще всего возникают у инженеров и разработчиков при организации резервирования.
Нужно ли останавливать контейнеры для бэкапа?
Только если вы копируете том напрямую (tar, rsync), и база в этот момент активно пишет данные. В таких ситуациях файловая структура может получиться неконсистентной. Если же вы используете pg_dump, mysqldump или другие штатные инструменты СУБД, то контейнеры останавливать не нужно.
Можно ли бэкапить базы без остановки контейнера?
Да. Большинство современных баз данных поддерживают горячие дампы, которые создаются без прерывания работы приложения. Это безопасный и стандартный способ резервирования.
Как восстанавливать быстрее, через дамп или через копию тома?
Обычно быстрее и надёжнее восстановить базу из дампа, потому что СУБД корректно пересоздаёт структуру и данные. Копия тома подходит только если база была остановлена перед созданием копии.
Что делать с секретами?
Секреты лучше хранить отдельно от бэкапов, в зашифрованном виде или в секрет-хранилищах вроде Vault или SOPS. Это снижает риск компрометации ключей.
Нужны ли инкрементальные копии?
Да, если объём данных значительный. Инкрементальные бэкапы уменьшают нагрузку на диск и сокращают время создания копий.
Выводы
Хорошая стратегия резервного копирования - это не роскошь, а необходимость. Docker позволяет создавать гибкие и масштабируемые системы, но не структура, а именно данные делают ваш проект ценным. И если не заботиться об их безопасности, то даже идеальная архитектура не спасёт от последствий сбоя.
Эффективный план резервирования должен включать регулярность, автоматизацию, геораспределённость и тестирование восстановления. Проекты, где резервирование интегрировано в DevOps-процессы, становятся устойчивыми и легко переживают любые инциденты. Чего и вам желаем!












