Контейнеризація давно стала поширеною і масовою практикою серед команд і адміністраторів IT-систем. Docker використовують і стартапи, і великі компанії, і невеликі команди розробників. Але разом із зручністю приходить і відповідальність, адже однієї помилки в конфігурації або збою диска достатньо, щоб проект опинився під загрозою масштабного збою, а в інших випадках і повного знищення, оскільки дані можуть бути втрачені, сервіс стане недоступним, а відновлення такого збою перетворюється на довгий і трудомісткий процес.
Щоб цього уникнути, резервне копіювання Docker-інфраструктури має бути не разовою дією, а частиною загальної архітектури. У цій статті ми розберемо ключові елементи такої системи, з'ясуємо, що саме потрібно бекапувати, які інструменти використовувати, пробіжимося по тому, які помилки допускають навіть досвідчені інженери і як побудувати стратегію, яка дійсно працює.
Що дійсно потрібно резервувати в Docker-інфраструктурі
Перш ніж налаштовувати будь-яку систему резервування, важливо зрозуміти, що саме в Docker-середовищі представляє цінність. Багато початківців-інженерів помилково намагаються «зробити бекап контейнера». Але контейнер - це всього лише виконуваний процес, а процеси немає сенсу зберігати. Зберігати необхідно дані та конфігурації, які забезпечують працездатність проекту.
Нижче ми з вами розберемо, які саме елементи Docker-інфраструктури підлягають резервуванню і чому.
Що відноситься до критичних компонентів
Щоб не витрачати ресурси на копіювання непотрібного, важливо розділяти дані за типами і цільовою цінністю. У кожного елемента інфраструктури є своя роль. Наприклад база даних забезпечує збереження і цілісність інформації, медіафайли - це користувацький контент, а docker-compose.yml зберігає архітектуру проекту.
Таблиця нижче показує, що дійсно необхідно бекапувати, і які інструменти краще для цього підходять.
| Тип даних |
Чи потрібно робити бекап? |
Чим робити бекап |
Коментар |
| PostgreSQL, MySQL, MongoDB |
Так |
pg_dump, mysqldump, mongodump |
Файли тому не можна копіювати під навантаженням |
| Файли, завантажені користувачами |
Так |
tar, rsync |
Найцінніша частина більшості проєктів |
| Кеш (Redis, Memcached) |
Зазвичай ні |
snapshot або skip |
Кеш легко відновити |
| Dockerfile, Compose, env |
Так |
Git |
Це «рецепт» сервісу |
| Docker-образи |
Іноді |
docker save |
Потрібно, якщо немає Dockerfile або збірка виконується вручну |
Чому томи повинні бути центром будь-якої стратегії резервування
Томи Docker - це сховище стану. Контейнер можна знищити і перестворити, але том насправді є його реальним вмістом, оскільки саме на томах зберігаються файли бази даних, файли користувачів та інші важливі артефакти. Тому будь-які обговорення резервування Docker-інфраструктури так чи інакше зводяться до роботи з томами.
Для розуміння, де фізично знаходиться том, можна використовувати наступну команду:
docker volume inspect my_volume
А для його архівування - просту команду tar:
sudo tar -czf media_backup_$(date +%F).tar.gz /var/lib/docker/volumes/my_volume/_data
Томи - найважливіша ланка, яку потрібно захищати, тому що саме вони відновлюють життєздатність проекту.
Реальний можливий сценарій збою
Для кращого розуміння уявіть собі інтернет-магазин, де база даних і медіа зберігаються на Docker-томах. Якщо контейнер MySQL раптово перестане працювати, то це дрібниці. Можна дуже швидко підняти новий контейнер з MySQL і вказавши йому місце зберігання даних - швидко відновити роботу сервісу.
Але якщо, з якоїсь причини, том /var/lib/mysql стане нечитабельним, то це означає, що зникнуть замовлення, транзакції, списки клієнтів і всі інші дані, критично важливі для проекту і бізнесу в цілому. Без нього проект фактично втрачений.
Однак, при наявності коректного бекапу, відновлення тому і роботи всього сервісу займе всього кілька хвилин.
Основні стратегії резервування Docker-даних
Існує кілька підходів до резервування, і кожен з них вирішує свої завдання. Універсального варіанту не існує, оскільки те, що підходить для невеликого блогу, може не підійти для системи з високим навантаженням.
У цьому розділі ми розберемо основні стратегії, їхні переваги, обмеження та варіанти застосування.
Огляд підходів до резервування та їхня застосовність
Перш ніж переходити до кожного методу, варто подивитися на загальну картину. Таблиця нижче допомагає зрозуміти, який варіант підходить саме вашому проекту.
| Метод |
Швидкість |
Надійність |
Складність |
Де застосовують |
| tar-архівування томів |
Середня |
Середня |
Низька |
Недорогі VPS, середні проєкти |
| Дамп баз даних |
Висока |
Висока |
Середня |
Бази з високою активністю |
| Знімки VM (snapshots) |
Дуже висока |
Висока |
Середня |
Proxmox, VMware, AWS |
| Хмарні сервіси резервування |
Висока |
Висока |
Середня |
S3, Backblaze, Wasabi |
| Restic + rclone |
Висока |
Дуже висока |
Середня |
CI/CD, DevOps-проєкти |
| GitOps |
Миттєва |
Максимальна |
Низька |
Усі типи проєктів |
Тепер давайте детальніше пробіжимося по кожному пункту і проведемо детальний розбір кожного підходу окремо.
1. Резервування томів через tar
Архівування томів - це один з найпростіших способів збереження даних. Він підходить для невеликих проектів, де обсяг інформації помірний, а інфраструктура розгорнута на одному хості.
Перевага цього підходу в його універсальності, оскільки tar працюватиме скрізь, де є доступ до файлової системи.
Приклад:
docker volume inspect project_data sudo tar -czf data_$(date +%F).tar.gz /var/lib/docker/volumes/project_data/_data
Обмеження:
- не забезпечує консистентність при активному записі в БД;
- повільно відновлюється на великих обсягах;
- погано підходить для високонавантажених систем.
2. Експорт даних баз через вбудовані інструменти
Для серйозних проектів кращим методом є резервування даних у вигляді дампів. Цей метод гарантує узгодженість стану таблиць, навіть якщо база працює під навантаженням.
Для цього методу застосовують спеціальні утиліти, які надає кожна СУБД, і їх застосування робить відновлення даних більш передбачуваним, простим, а головне безпечним. Давайте подивимося на приклади для різних СУБД.
PostgreSQL:
pg_dump -U user -F c -f backup.dump projectdb
MySQL:
mysqldump -u user -p database > dump.sql
MongoDB:
mongodump --out /backups/mongo_$(date +%F)
Такий підхід підходить практично для всіх виробничих систем, у тому числі при активному зростанні даних.
3. Знімки томів і віртуальних дисків (snapshots)
Віртуалізація (Hyper-V, VMware, AWS EC2) дозволяє робити моментальні знімки файлової системи. Це швидкий і надійний спосіб резервування.
Основна ідея snapshot-підходу полягає в «заморожуванні» стану дисків в конкретний момент часу. Він ефективний при великих обсягах даних, коли звичайний бекап займав би години.
Знімки хороші, якщо:
- проект працює на віртуальних машинах;
- дані активно змінюються;
- важлива висока швидкість відновлення.
4. GitOps для конфігурацій
Конфігурації - це основа передбачуваності. Без docker-compose.yml, Dockerfile і змінних середовища відновлення втрачає структуру і перетворюється на вгадування параметрів.
GitOps підхід передбачає, що:
- всі конфігурації зберігаються в Git;
- інфраструктура описана декларативно;
- сервер можна «відтворити» з репозиторію.
Це не замінює бекап даних, але доповнює його, роблячи відновлення швидким і, що важливо, повторюваним.
Як побудувати грамотний план резервного копіювання Docker
Ефективне резервування - це не тільки вибір інструментів. Це процес, який повинен бути регулярним, документованим і автоматизованим. У цьому розділі ми розглянемо ключові елементи робочого плану, який можна використовувати в будь-якій Docker-інфраструктурі.
Визначення критичних даних
Кожен проект має унікальну структуру цінності. Для e-commerce найбільш важливі таблиці замовлень, для медіа-сервісів - завантажені файли, для SaaS - дані користувачів. Визначення критичних точок і є основою плану резервування.
Частота резервування
Ритм копіювання повинен відповідати ритму оновлення даних:
- високонавантажені бази - від декількох разів на годину;
- CMS, блоги - раз на добу;
- великі проекти - інкрементальні копії.
Правильно обрана частота знижує навантаження на сервер і забезпечує актуальність копій.
Георозподіленість копій
Зберігати резервні файли на тому ж сервері, де працюють контейнери - це прямий шлях до втрати даних.
Необхідно зберігати копії на сервері в іншому дата-центрі, на S3, NAS або виділеному VPS.
Тестування відновлення
Будь-який бекап повинен бути перевірений. Інакше він перетворюється лише на ілюзію безпеки. Тому хоча б раз на місяць слід розгортати тестове середовище і перевіряти, що відновлення проекту проходить повністю і без збоїв.
Типова архітектура резервування Docker-проекту
Робоча архітектура зазвичай виглядає як ланцюжок компонентів. Це допомагає забезпечити контроль на кожному етапі і автоматизувати процес.
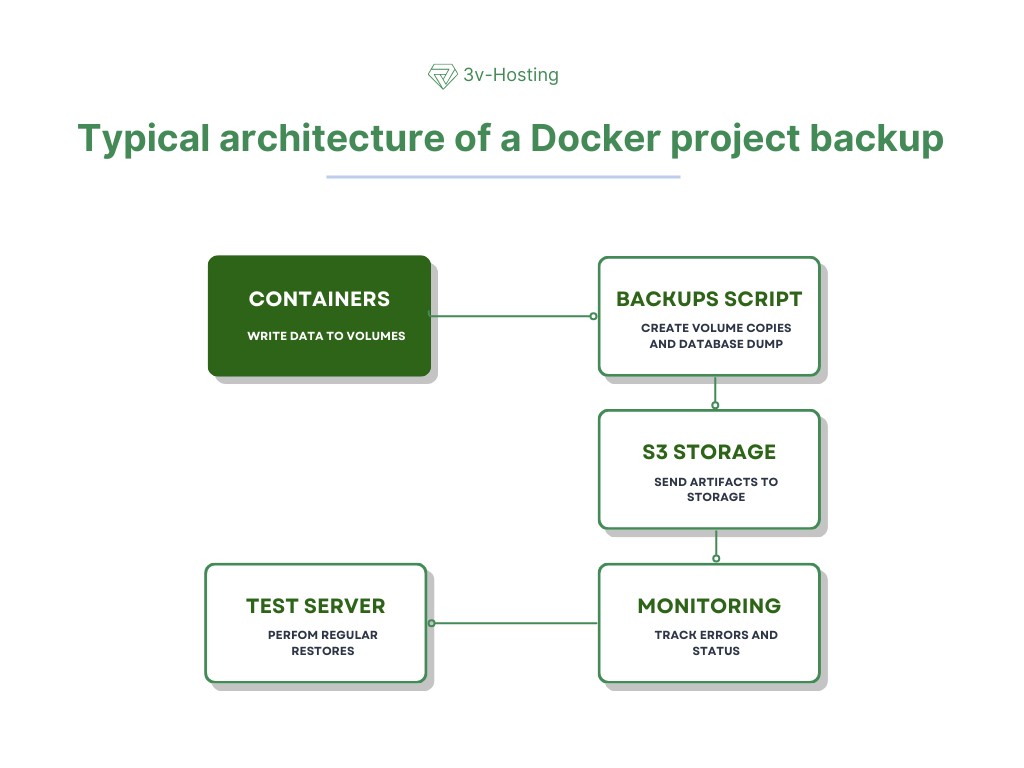
Контейнери записують дані в томи.
Кожен сервіс працює всередині власного контейнера, але всі важливі дані - бази, медіафайли, кеші - зберігаються у виділених томах. Це забезпечує їх незалежність від контейнера і робить можливим подальше резервування.
Скрипт створює копії томів і дампи баз.
За розкладом запускається автоматизований скрипт або утиліта, яка послідовно робить дампи баз даних і архівує потрібні томи. На цьому етапі формуються повноцінні бекап-артефакти.
Артефакти відправляються в S3 або інший storage.
Отримані файли завантажуються в віддалене сховище: об'єктне S3-сховище, FTP, окремий сервер або NAS. Це захищає дані від втрати при збої основного хоста.
На тестовому сервері регулярно проводиться відновлення.
Щоб переконатися, що бекапи дійсно працюють, їх періодично розгортають на окремому стенді. Це дозволяє заздалегідь виявляти проблеми, які могли б проявитися тільки в момент реального відновлення.
Моніторинг відстежує помилки і статус виконання.
Всі процеси резервування логіруються і відправляються в систему спостереження (наприклад, Prometheus або Grafana). Якщо копіювання не виконано, перервано або пройшло з помилками, команда отримує сповіщення і може оперативно відреагувати.
Помилки, які допускають навіть досвідчені інженери
Навіть ті, хто багато років працює з Docker, іноді роблять помилки, які призводять до втрати даних. Частково це пов'язано з тим, що Docker часто створює помилкове відчуття безпеки.
До основних помилок відносяться:
- зберігання копій на тому ж диску;
- відсутність дампів баз даних;
- ігнорування секретів;
- відсутність логування бекапів;
- відсутність версій резервних копій;
- зберігання даних без шифрування.
Кожна з цих помилок усувається відносно просто, якщо включити резервування в DevOps-процеси.
Інструменти для автоматизації резервування
Зі збільшенням кількості контейнерів і даних у вашому проекті, ручне резервування стає громіздким і незручним. Тому автоматизація повинна бути обов'язковою частиною вашої інфраструктури. Зручними інструментами для автоматизації є наступні інструменти:
Bash-скрипти
Для невеликих Docker-хостів достатньо звичайних bash-скриптів. Вони дозволяють повністю керувати процесом і легко адаптуються до будь-яких вимог.
Restic і rclone
Restic - це потужний інструмент, який підтримує шифрування, дедуплікацію та інкрементальні копії. У поєднанні з rclone він чудово підходить для завантаження даних у S3 або Backblaze.
Velero
Хоча Velero асоціюється з Kubernetes, його використовують і для Docker-проектів, яким потрібна складна логіка відновлення.
Docker Compose Backups (DCP)
Готові утиліти, здатні автоматично створювати архіви томів за розкладом.
Приклад схеми резервування невеликого проекту
Невеликі проекти (наприклад, додаток + PostgreSQL + Nginx) можуть використовувати просту, але ефективну структуру бекапів.
Каталоги:
/backups/
├── db/
├── media/
├── configs/
└── logs/
Найпростіший алгоритм:
- Виконати pg_dump;
- Архівувати медіа том;
- Зберегти конфігурації в Git;
- Відправити файли на S3;
- Очистити старі копії через logrotate.
Такий підхід робить відновлення швидким і повторюваним.
Багатошарова стратегія резервування
Надійний підхід передбачає наявність декількох рівнів резервного копіювання, кожен з яких має свої цілі.
| Рівень |
Частота |
Призначення |
| Гарячі копії |
раз на 1–4 години |
Швидке відновлення |
| Повні копії |
щодня |
Захист від збоїв |
| Довгострокові копії |
щомісяця |
Повернення до попередніх станів |
Ця схема часто допомагає захищатися від помилок користувачів, критичних багів, випадкових видалень і апаратних збоїв.
FAQ щодо резервного копіювання Docker
Цей розділ відповідає на найпоширеніші питання, які найчастіше виникають у інженерів і розробників при організації резервування.
Чи потрібно зупиняти контейнери для бекапу?
Тільки якщо ви копіюєте том безпосередньо (tar, rsync), і база в цей момент активно записує дані. У таких ситуаціях файлова структура може виявитися неконсистентною. Якщо ж ви використовуєте pg_dump, mysqldump або інші штатні інструменти СУБД, то контейнери зупиняти не потрібно.
Чи можна створювати бекапи баз без зупинки контейнера?
Так. Більшість сучасних баз даних підтримують гарячі дампи, які створюються без переривання роботи додатка. Це безпечний і стандартний спосіб резервування.
Як відновлювати швидше, через дамп або через копію тому?
Зазвичай швидше і надійніше відновити базу з дампа, тому що СУБД коректно перестворює структуру і дані. Копія тому підходить тільки якщо база була зупинена перед створенням копії.
Що робити з секретами?
Секрети краще зберігати окремо від бекапів, в зашифрованому вигляді або в секретних сховищах на зразок Vault або SOPS. Це знижує ризик компрометації ключів.
Чи потрібні інкрементальні копії?
Так, якщо обсяг даних значний. Інкрементальні бекапи зменшують навантаження на диск і скорочують час створення копій.
Висновки
Хороша стратегія резервного копіювання - це не розкіш, а необхідність. Docker дозволяє створювати гнучкі та масштабовані системи, але не структура, а саме дані роблять ваш проект цінним. І якщо не дбати про їхню безпеку, то навіть ідеальна архітектура не врятує від наслідків збою.
Ефективний план резервування повинен включати регулярність, автоматизацію, георозподіленість і тестування відновлення. Проекти, де резервування інтегровано в DevOps-процеси, стають стійкими і легко переживають будь-які інциденти. Чого і вам бажаємо!












