Когда VPS начинает работать медленнее обычного, то многие администраторы действуют по привычному сценарию: подключаются по SSH, открывают top или htop, смотрят потребление памяти через free -m, проверяют дисковое пространство командой df -h. Да, такой подход помогает понять, что происходит с сервером прямо сейчас.
Но есть одна проблема. Если всплеск нагрузки случился десять минут назад и к моменту проверки уже закончился, то увидеть его следы удаётся далеко не всегда. Сервер снова выглядит здоровым, а причина тормозов остаётся неизвестной.
Становится очевидной необходимость мониторинга сервера и если раньше мониторинг настраивали в основном на каких-то крупных проектах с весьма разветвленной инфраструктурой, то сейчас данный вопрос актуален и для отдельных серверов, особенно выступающих в роли гипервизора, например для Docker контейнеров. Всегда, даже на небольшом VPS полезно иметь под рукой историю загрузки процессора, памяти, дисков и сети. Иначе многие сбои приходится расследовать практически вслепую.
И, казалось бы, в нашем блоге уже была статья на тему мониторинга VPS. Но тут есть один нюанс и заключается он в относительной сложности современных решений для мониторинга. Например популярные системы вроде Prometheus, Grafana или Zabbix дают огромные возможности, но за них приходится платить своим временем, так как нужно разбираться с настройкой, хранением метрик, уведомлениями, дашбордами и тд. Плюс, иногда под мониторинг необходимо выделять отдельный сервер.
И как вы понимаете, для небольшого проекта такой подход очевидно является избыточным.
Именно в таких случаях Netdata выглядит довольно практичным решением, так как его установка занимает всего несколько минут, после чего система сразу начинает собирать сотни метрик и показывать их в удобном веб-интерфейсе практически в реальном времени. И всё это достаточно легковесное, чтобы уместиться даже на самом простом сервере и не потреблять много ресурсов.
Что такое Netdata
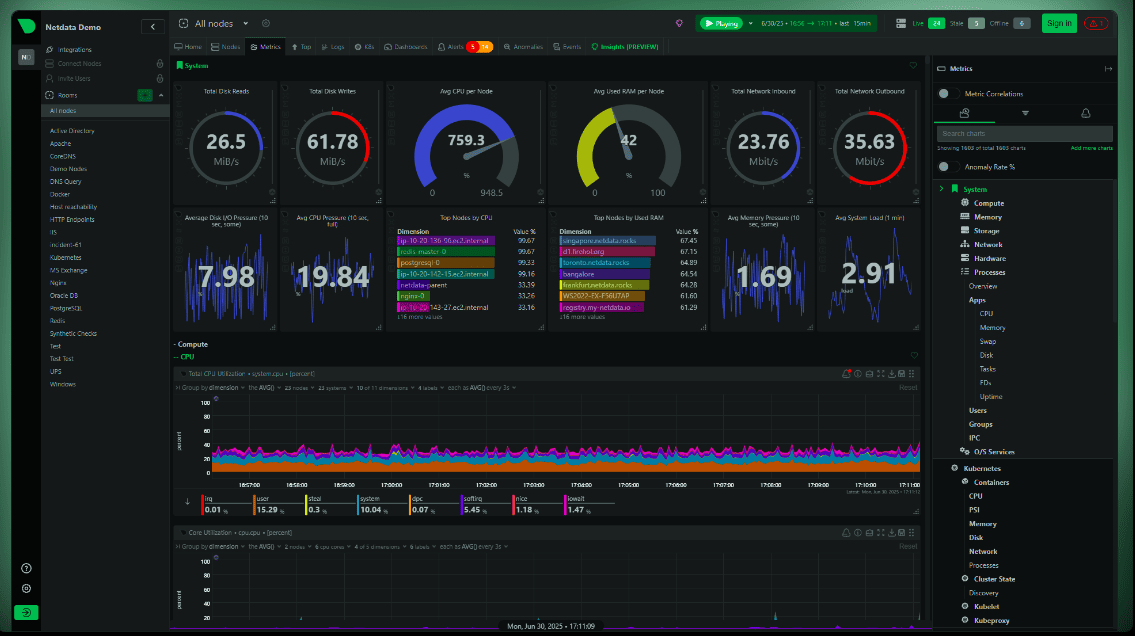
Netdata - это система мониторинга с открытым исходным кодом, предназначенная для анализа состояния серверов, виртуальных машин, контейнеров и приложений в режиме реального времени.
После установки она автоматически обнаруживает большинство компонентов системы и начинает собирать данные без необходимости вручную создавать дашборды, настраивать экспортёры или писать правила сбора метрик. Фактически Netdata превращает VPS в прозрачную систему, где можно увидеть практически всё происходящее на сервере через единый веб-интерфейс. Вместо десятков консольных команд администратор получает набор интерактивных графиков, позволяющих быстро определить источник проблемы.
Главное отличие Netdata от многих других платформ мониторинга заключается в ориентации на оперативную диагностику. Если Grafana и Prometheus часто используются для анализа тенденций за месяцы и годы, то Netdata помогает быстро ответить на вопрос: что происходит с сервером прямо сейчас и что происходило несколько минут назад.
Сколько ресурсов потребляет Netdata
Один из самых часто задаваемых вопросов, которые задают перед установкой той или иной системы мониторинга - это вопрос, не станет ли система мониторинга сама причиной дополнительной нагрузки. И вот как мы упомянули выше - Netdata считается достаточно лёгким решением.
В случае с Netdata такие опасения обычно не подтверждаются, так как проект изначально разрабатывался с прицелом на постоянный сбор большого количества метрик без заметного влияния на работу сервера. Для этого большая часть данных обрабатывается локально, без сложных запросов к внешним базам данных и без необходимости постоянно передавать большие объёмы информации на отдельный сервер мониторинга.
Ещё одна причина низкого потребления ресурсов заключается в архитектуре самого решения. Netdata получает метрики напрямую из операционной системы и приложений, хранит большую часть оперативных данных в памяти и оптимизирован для работы в режиме реального времени. За счёт этого системе не приходится выполнять тяжёлые вычисления или постоянно обращаться к диску.
Для типичного VPS можно ориентироваться на следующие показатели:
| Ресурс |
Примерное потребление |
| CPU |
менее 1–2% |
| Оперативная память |
100–300 МБ |
| Дисковое пространство |
зависит от настроек хранения |
| Сетевой трафик |
минимальный |
Конечно, конкретные цифры зависят от количества собираемых метрик, числа контейнеров, баз данных и других сервисов на сервере. Например, если на VPS работает несколько десятков Docker-контейнеров, то нагрузка очевидно будет немного выше. А если это небольшой веб-сервер с простым сайтом и базой данных, тогда существенно ниже.
Причём бывают случаи, когда администраторы устанавливают Netdata даже на виртуальные машины с 1-2 ГБ оперативной памяти и не замечают какого-либо влияния на производительность. Пожалуй, именно поэтому данный инструмент часто используют не только на крупных серверах, но и на небольших VPS, где каждый мегабайт ресурсов имеет значение.
Какие показатели можно отслеживать
Сразу после установки Netdata начинает собирать большое количество метрик автоматически. Никакой первоначальной настройки обычно не требуется, ведь система сама обнаруживает доступные устройства, службы и приложения, а затем начинает отображать данные в веб-интерфейсе.
Набор доступных показателей получается довольно внушительным и содержит такие метрики:
- Загрузка процессора - общая нагрузка на CPU, распределение по ядрам, системное и пользовательское время, ожидание ввода-вывода;
- Использование оперативной памяти - занятая и свободная память, кеширование, буферы, распределение памяти между процессами;
- Работа swap - объём используемого swap-раздела и интенсивность обращения к нему. Полезно при поиске нехватки оперативной памяти;
- Скорость чтения и записи дисков - текущая нагрузка на накопители, количество операций ввода-вывода и задержки доступа к дискам;
- Сетевой трафик - входящий и исходящий поток данных, нагрузка на сетевые интерфейсы, объём переданной информации;
- Количество соединений - активные TCP и UDP-сессии, состояние сетевых подключений и нагрузка на сетевой стек;
- Активность процессов - какие приложения потребляют процессорное время и память в данный момент;
- Загрузка файловой системы - использование дискового пространства по разделам и точкам монтирования;
- Показатели Docker-контейнеров - потребление ресурсов каждым контейнером, сетевой трафик и активность процессов внутри контейнеров;
- Статистика веб-серверов - данные от Nginx, Apache и других поддерживаемых серверов при наличии соответствующих модулей;
- Показатели баз данных - активность MySQL, MariaDB, PostgreSQL, Redis и других популярных СУБД.
Но на этом список не заканчивается. Например, Netdata умеет показывать температуру оборудования (если датчики доступны системе), статистику RAID-массивов, состояние служб systemd, данные виртуализации и огромное множество других параметров.
В результате администратор получает не отдельные цифры из разных утилит, а единую картину происходящего на сервере. Иногда этого достаточно, чтобы за несколько минут найти причину проблем, на поиск которой через консоль пришлось бы потратить значительно больше времени.
Установка на Linux-сервер
Одна из причин популярности Netdata - это очень простой процесс установки. Если многие системы мониторинга требуют подготовки базы данных, настройки агентов и ручного создания дашбордов, то здесь всё значительно проще.
Для большинства современных дистрибутивов Linux достаточно выполнить официальный скрипт установки:
wget -O /tmp/netdata-kickstart.sh https://get.netdata.cloud/kickstart.sh
sh /tmp/netdata-kickstart.sh
Этот скрипт самостоятельно определит операционную систему, установит необходимые зависимости, загрузит актуальную версию Netdata и зарегистрирует службу в системе. Данный процесс обычно занимает всего несколько минут.
После завершения установки сервис запускается автоматически. Проверить его состояние можно командой:
systemctl status netdata
По умолчанию веб-интерфейс становится доступен на порту 19999 и перейти в него вы можете, например так:
http://IP_СЕРВЕРА:19999
Однако, если между вами и сервером находится файервол, то этот порт может потребоваться открыть отдельно. В противном случае браузер просто не сможет подключиться к интерфейсу мониторинга.
На этом этапе многие администраторы совершают типичную ошибку - просто открывают порт 19999 для всего интернета и оставляют его в таком виде. Да, для тестов и на время настройки это может показаться удобным решением, но в рабочей среде так делать не стоит никогда!
Всё-таки это административный интерфейс сервера и любой дополнительный сервис, доступный снаружи, увеличивает поверхность возможной атаки. Поэтому даже если в самом Netdata нет известных проблем безопасности, то хорошей практикой, всё таки, считается ограничение доступа ко всем служебным панелям.
Обычно используют один из следующих вариантов:
- доступ только с доверенных IP-адресов через файервол;
- подключение через VPN;
- публикация интерфейса через Nginx или Apache в роли обратного прокси;
- дополнительную HTTP-аутентификацию перед доступом к панели.
Конечно, для домашнего сервера или тестовой виртуальной машины это может показаться излишней осторожностью. Но для любого публичного VPS с белым IP-адресом такие меры уже относятся к базовой гигиене безопасности.
Сразу после первого запуска Netdata начинает собирать метрики. Никаких дополнительных агентов, ручного подключения устройств или создания графиков не требуется. Через несколько секунд после открытия веб-интерфейса уже можно увидеть загрузку процессора, использование памяти, сетевую активность и другие показатели сервера в режиме реального времени.
Ну разве это не чудо? :)
Публикация Netdata через Nginx
Если мониторингом нужно пользоваться регулярно, то открывать порт 19999 напрямую обычно нет смысла. Гораздо удобнее и безопаснее опубликовать интерфейс через Nginx и использовать привычное доменное имя.
Заодно отпадает необходимость держать дополнительный порт доступным извне. Пользователь будет работать с Netdata через стандартный HTTP или HTTPS, а сам сервис останется доступен только локально на сервере.
Простейшая конфигурация Nginx для публикации Netdata выглядит так:
location /netdata/ {
proxy_pass http://127.0.0.1:19999/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
После применения конфигурации и перезагрузки Nginx интерфейс мониторинга станет доступен по адресу вида:
https://example.com/netdata/
Такой подход даёт сразу несколько преимуществ. Например соединение можно защитить SSL-сертификатом, использовать существующие правила файервола и централизованно управлять доступом через веб-сервер. А если мониторингом пользуются несколько администраторов, то дополнительно можно включить HTTP-аутентификацию. В этом случае, перед открытием панели, Nginx будет запрашивать логин и пароль.
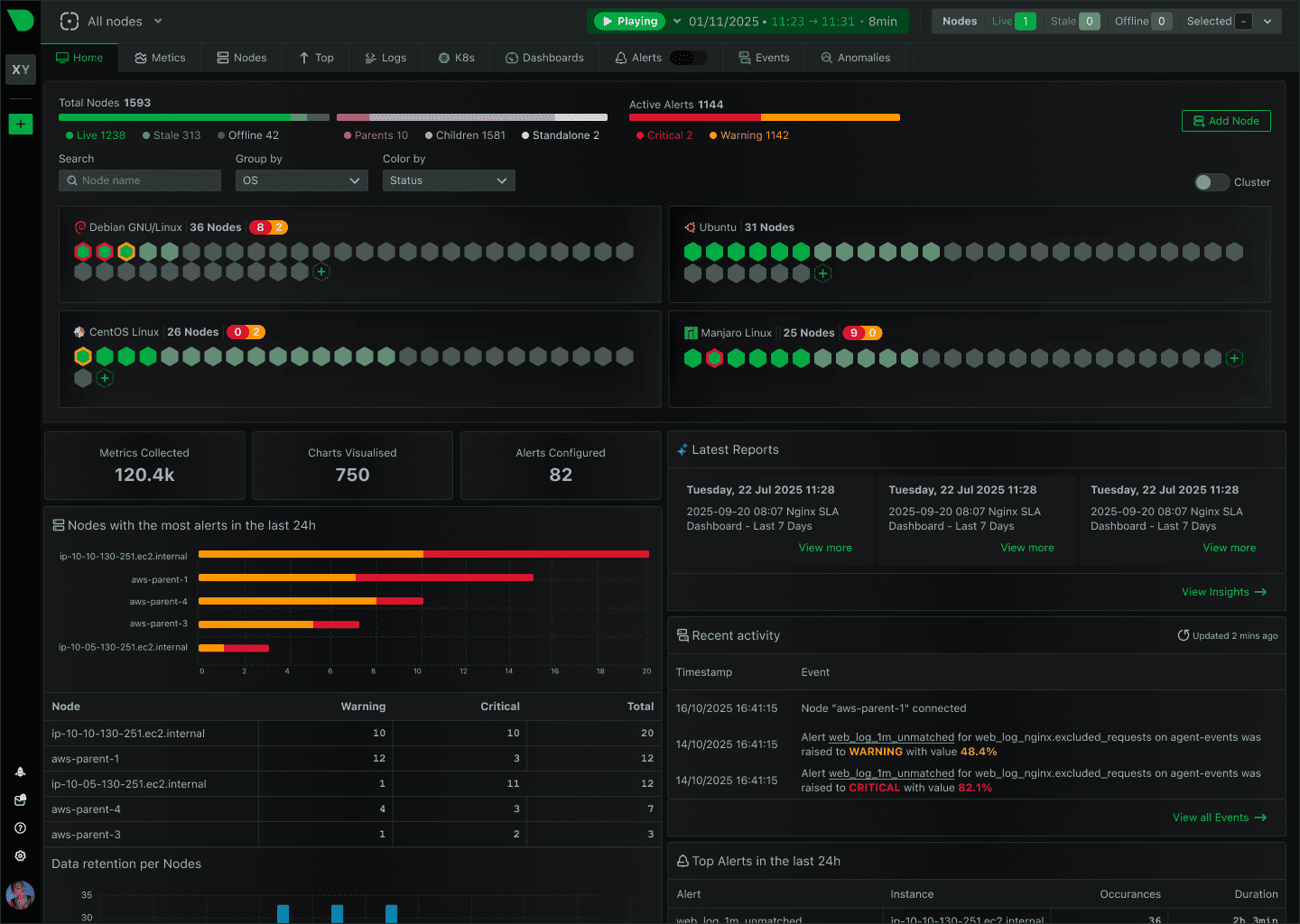
Первое знакомство с интерфейсом
Первое открытие Netdata у многих вызывает примерно одинаковую реакцию: слишком много графиков.
Экран буквально заполнен диаграммами, цифрами и показателями, что поначалу сбивает с толку, особенно если раньше ваш мониторинг ограничивался командами top, htop и просмотром логов в консоли сервера.
Но через несколько минут спокойного ознакомления становится понятно, что хаоса тут нет. Интерфейс сгруппирован по категориям, а основные показатели находятся буквально на первых экранах.
Чаще всего администраторы обращаются к нескольким разделам:
- CPU - общая загрузка процессора, распределение нагрузки по ядрам, системное и пользовательское время;
- Memory - использование оперативной памяти, кешей, буферов и swap;
- Disk - скорость чтения и записи, количество операций ввода-вывода, задержки работы накопителей;
- Network - сетевой трафик, количество соединений и нагрузка на интерфейсы;
- Applications - показатели отдельных сервисов и приложений, если Netdata смог их обнаружить.
Любой график можно прокрутить назад и посмотреть, что происходило несколько минут, часов или даже дней назад (зависит от настроек хранения данных). Если пользователь сообщил, что сайт был недоступен в 14:17, можно открыть этот временной интервал и увидеть, что происходило на сервере именно тогда.
Собственно, ради таких ситуаций мониторинг и устанавливают. Не для красивых графиков, а для возможности увидеть проблему уже после того, как она произошла.
Мониторинг Docker-контейнеров и WordPress
Как мы знаем, сегодня всё больше проектов разрабатываются на основе Docker-контейнеров. Бывает, что даже относительно простой сайт может состоять из нескольких отдельных микросервисов, таких как веб-серверы, базы данных, Redis, очередь задач и других компонентов.
Netdata хорошо подходит для такой инфраструктуры, поскольку после установки автоматически обнаруживает запущенные контейнеры и начинает собирать статистику по каждому из них отдельно.
Для контейнеров доступны данные о:
- загрузке процессора;
- потреблении оперативной памяти;
- сетевом трафике;
- операциях чтения и записи;
- количестве процессов внутри контейнера.
Представим VPS, на котором WordPress работает в Docker вместе с MariaDB и Redis. Пользователи начинают жаловаться на медленную загрузку страниц. Общая загрузка сервера действительно высокая, но по обычным системным метрикам не всегда понятно, какой именно сервис создаёт проблему.
Netdata позволяет посмотреть нагрузку по каждому контейнеру отдельно. Иногда оказывается, что вся проблема связана с базой данных. В другой ситуации резко выросло потребление памяти контейнером PHP-FPM. Бывает и так, что узким местом становится Redis или дисковая подсистема. И всё это великолепие отлично видно на одном простом дашборде.
Для WordPress и вовсе такие сценарии встречаются довольно часто. Например, после публикации популярной статьи на вашем сайте, запуска рекламной кампании или попадания материала в рекомендации поисковых систем - посещаемость сайта может резко увеличиться.
И именно в такой ситуации обычно начинают проявляться ограничения сервера:
- заканчивается свободная оперативная память;
- растёт нагрузка на MySQL или MariaDB;
- увеличивается число PHP-процессов;
- возрастает нагрузка на диски;
- появляются задержки при обработке запросов.
Пытаться анализировать такие ситуации через набор консольных утилит не всегда удобно, особенно если проблема уже исчезла к моменту подключения к серверу по SSH.
В Netdata все основные показатели отображаются одновременно на одном экране. Можно быстро посмотреть историю нагрузки, увидеть, какой контейнер потреблял ресурсы в момент сбоя, и понять, хватает ли текущей конфигурации VPS для существующей посещаемости. По этой причине Netdata часто используют не только для поиска неисправностей, но и для планирования дальнейшего роста проекта. Когда ресурсов начинает не хватать, это становится заметно задолго до того, как сервер начнёт отказывать пользователям. Впрочем это одна из важнейших задач любого мониторинга.
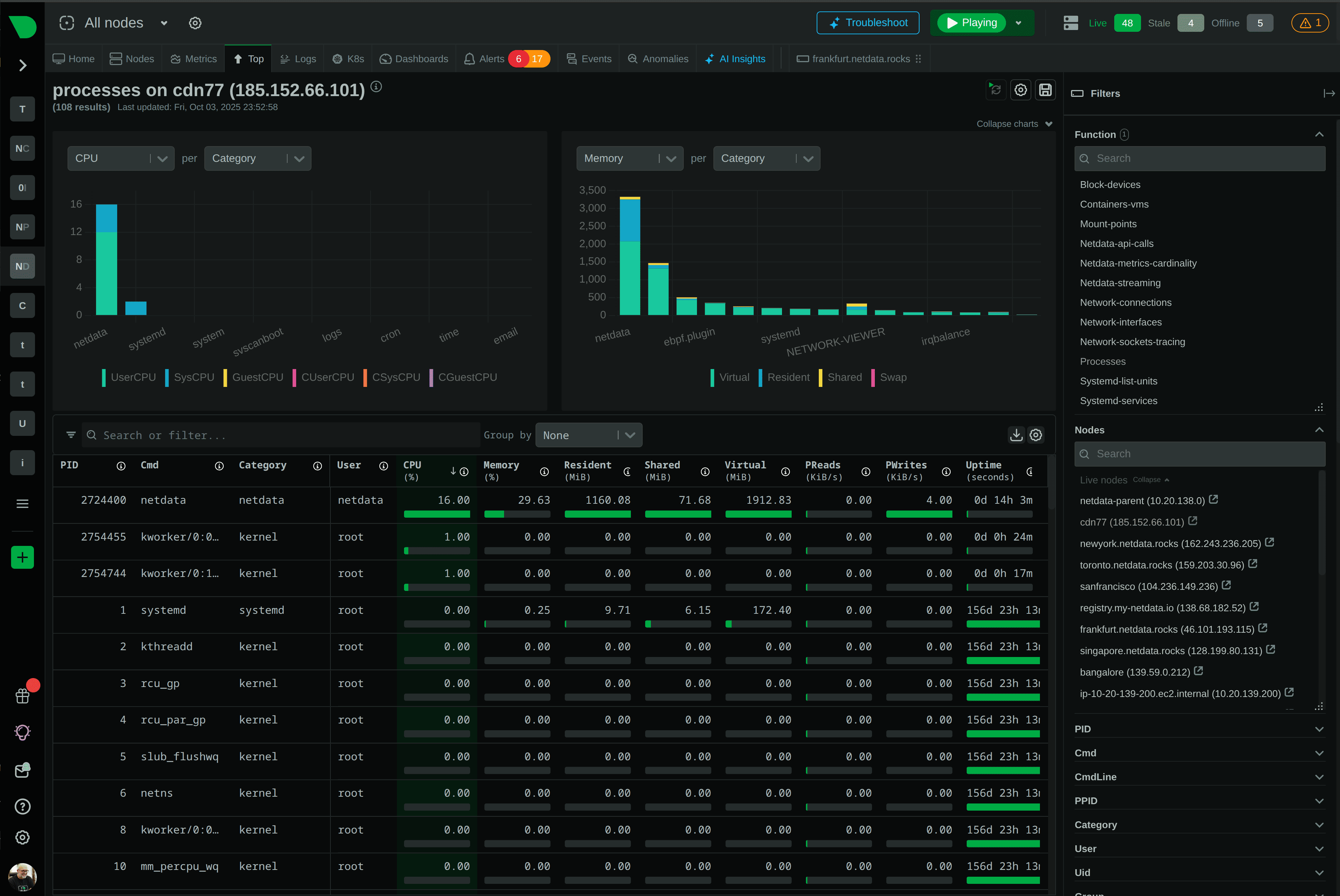
Уведомления о проблемах
Даже самый подробный мониторинг бесполезен, если администратор замечает проблему спустя несколько часов после её появления. Но ведь и постоянно держать вкладку Netdata открытой никто не будет. Особенно если серверов несколько, а мониторинг используется скорее для контроля состояния инфраструктуры, чем для непрерывного наблюдения за графиками.
Поэтому в Netdata предусмотрена система автоматических уведомлений. Сервис умеет отслеживать различные отклонения от нормальной работы и отправлять сообщения при возникновении проблем, например, если процессор какое-то время работает под высокой нагрузкой, заканчивается оперативная память на сервере или файловая система приближается к заполнению.
Поддерживается несколько способов доставки уведомлений:
- Email;
- Telegram;
- Discord;
- Slack;
- Webhook и другие интеграции.
Это особенно удобно для небольших проектов, где нет круглосуточной команды администраторов. Поэтому вместо постоянной проверки графиков система сама сообщает о возникшей проблеме.
Для многих владельцев VPS именно уведомления становятся самой полезной частью системы мониторинга, ведь сами графики помогают разобраться в причинах сбоя, а вот оповещения позволяют узнать о нём вовремя.
Выбор между Netdata, Prometheus и Zabbix
Вопрос выбора системы мониторинга возникает почти у каждого администратора после первого серьёзного сбоя на сервере. Ответ здесь зависит не столько от возможностей конкретного продукта, сколько от размеров инфраструктуры и задач, которые предстоит решать.
Ниже приведено общее, упрощенное сравнение популярных решений:
| Возможность |
Netdata |
Prometheus + Grafana |
Zabbix |
| Простая установка |
Да |
Нет |
Нет |
| Быстрый старт |
Да |
Нет |
Частично |
| Долгосрочное хранение данных |
Ограничено |
Да |
Да |
| Мониторинг одного VPS |
Отлично |
Избыточно |
Избыточно |
| Kubernetes |
Базово |
Отлично |
Хорошо |
| Сложные дашборды |
Ограниченно |
Отлично |
Хорошо |
| Масштабирование на десятки серверов |
Частично |
Отлично |
Отлично |
Если задача заключается в мониторинге одного VPS, нескольких сайтов или небольшого набора серверов, то Netdata часто оказывается самым быстрым способом получить полезный результат. Установка занимает считанные минуты, а графики появляются практически сразу.
С Prometheus ситуация другая. Это мощная платформа для хранения и обработки метрик, которая особенно хорошо показывает себя в больших инфраструктурах, Kubernetes-кластерах и средах с десятками или сотнями сервисов. Но вместе с гибкостью появляется и сложность. Нужно настраивать сбор данных, хранение метрик, визуализацию, правила оповещений.
Zabbix находится где-то посередине. Он умеет очень многое, хорошо подходит для корпоративных сетей и крупных инфраструктур, но требует значительно больше времени на первоначальное внедрение по сравнению с Netdata.
Есть ещё один момент, который редко обсуждают в сравнительных обзорах. Когда сервер начинает работать нестабильно, администратору часто нужен ответ прямо сейчас. Не через отчёты, не через сложные запросы к базе метрик, а буквально в течение нескольких секунд. Открыть страницу и увидеть, что происходило с процессором, памятью или дисками в момент сбоя. И вот именно в таких ситуациях Netdata показывает себя особенно хорошо.
Когда Netdata уже недостаточно
При всех своих достоинствах Netdata всё-же остаётся инструментом, ориентированным прежде всего на отдельные серверы и оперативную диагностику.
Однако если ваша инфраструктура состоит из десятков машин, нескольких Kubernetes-кластеров, множества микросервисов и требует хранения метрик в течение месяцев или лет, то, пожалуй, возможностей Netdata может оказаться недостаточно.
В таких проектах обычно используют Prometheus, Grafana, VictoriaMetrics, Zabbix и другие специализированные платформы. Они лучше подходят для централизованного сбора данных, сложной аналитики и долгосрочного хранения истории.
Любопытно, что переход на более крупную систему мониторинга далеко не всегда означает отказ от Netdata. Во многих компаниях он продолжает работать параллельно. Глобальный мониторинг ведётся через Prometheus или Zabbix, а Netdata используется непосредственно на серверах для быстрого анализа проблем в режиме реального времени.
Часто задаваемые вопросы
Подходит ли Netdata для VPS с 1 ГБ памяти?
Да, установить его можно даже на такой сервер. Однако нужно помнить, что сам мониторинг тоже потребляет ресурсы. И если на VPS уже работает база данных, веб-сервер и несколько приложений, дополнительное потребление памяти может оказаться заметным. Для более комфортной работы обычно рекомендуют серверы с 2 ГБ RAM и выше.
Можно ли использовать Netdata бесплатно?
Да. Базовой версии достаточно для большинства задач, связанных с мониторингом VPS, Docker-контейнеров, веб-серверов и баз данных. Для небольших проектов её возможностей обычно хватает с запасом.
Работает ли Netdata с Docker?
Да. После установки система автоматически обнаруживает запущенные контейнеры и начинает собирать статистику по каждому из них. Отдельная настройка в большинстве случаев не требуется.
Можно ли получать уведомления в Telegram?
Да. Telegram входит в список поддерживаемых каналов доставки уведомлений. Помимо него доступны Email, Discord, Slack, Webhook и другие варианты интеграции.
Чем Netdata отличается от Grafana?
Сравнивать эти продукты напрямую не совсем корректно, поскольку задачи у них частично отличаются. Netdata ориентирован на максимально быстрый запуск и оперативную диагностику сервера в режиме реального времени. Grafana-же чаще используется как платформа визуализации для данных, которые собираются другими системами мониторинга, например Prometheus.
Можно ли установить Netdata на Ubuntu 24.04?
Да. Netdata без проблем работает на современных версиях Ubuntu, включая Ubuntu 24.04 LTS. Официальный установочный скрипт самостоятельно определяет дистрибутив и выполняет необходимые действия.
Можно ли мониторить несколько серверов одновременно?
Да. Для этого предусмотрены инструменты централизованного просмотра данных. Такой режим удобен, если в инфраструктуре несколько VPS и нужно быстро переключаться между ними из одного интерфейса.
Подходит ли Netdata для продакшн-серверов?
Да. Netdata активно используется на рабочих серверах, в том числе в коммерческих проектах. Благодаря невысокому потреблению ресурсов его можно устанавливать как на небольшие VPS, так и на достаточно нагруженные системы.
Может ли Netdata заменить Prometheus или Zabbix?
Для одного сервера или небольшого количества VPS - часто может. Однако, если требуется централизованный мониторинг большой инфраструктуры, длительное хранение метрик и сложная аналитика, то возможностей специализированных платформ обычно больше. Всё зависит от масштаба проекта и поставленных задач.
Выводы
Итак, проблема большинства серверов заключается не в том, что они ломаются слишком часто, а в том, что причины сбоев обычно становятся известны уже после того, как всё закончилось. Например сайт несколько минут отвечал медленно, база данных внезапно загрузила процессор или один из контейнеров начал потреблять всю доступную память, а администратор подключился к серверу уже тогда, когда показатели вернулись к нормальным значениям.
Без мониторинга такие ситуации превращаются в сущие догадки.
Netdata решает эту задачу довольно простым способом. Установка занимает всего несколько минут, после чего сервер начинает сохранять историю своей работы и отображать её в удобном интерфейсе. Можно увидеть нагрузку на процессор, использование памяти, активность дисков, сетевой трафик, работу контейнеров и приложений. Причём не только сейчас, но и в тот момент, когда возникла проблема.
Для владельцев простых VPS это полезный инструмент не только для поиска неисправностей, но и для прогнозирования времени будущего апгрейда сервера, исходя из графиков нагрузки на те или иные компоненты системы.
Конечно, для крупных инфраструктур с десятками серверов обычно используют более сложные платформы мониторинга. Но для одного VPS, небольшого проекта, WordPress-сайта, интернет-магазина или собственного сервера приложений - возможностей Netdata зачастую хватает "с головой".
По сути, это один из самых простых способов начать следить за состоянием сервера не по ощущениям, а по реальным данным. И часто именно такой подход помогает обнаружить проблему задолго до того, как она превратится в полноценный сбой.












