Коли VPS починає працювати повільніше, ніж зазвичай, багато адміністраторів діють за звичним сценарієм: підключаються через SSH, відкривають top або htop, перевіряють використання пам’яті за допомогою free -m, перевіряють дисковий простір командою df -h. Так, такий підхід допомагає зрозуміти, що саме зараз відбувається з сервером.
Але є одна проблема. Якщо сплеск навантаження стався десять хвилин тому і до моменту перевірки вже закінчився, то побачити його сліди вдається далеко не завжди. Сервер знову виглядає здоровим, а причина гальмування залишається невідомою.
Стає очевидною необхідність моніторингу сервера, і якщо раніше моніторинг налаштовували в основному на якихось великих проєктах з досить розгалуженою інфраструктурою, то зараз це питання актуальне і для окремих серверів, особливо тих, що виступають у ролі гіпервізора, наприклад для Docker-контейнерів. Завжди, навіть на невеликому VPS, корисно мати під рукою історію завантаження процесора, пам'яті, дисків і мережі. Інакше багато збоїв доводиться розслідувати практично наосліп.
І, здавалося б, у нашому блозі вже була стаття на тему моніторингу VPS. Але тут є один нюанс, і полягає він у відносній складності сучасних рішень для моніторингу. Наприклад, популярні системи на кшталт Prometheus, Grafana або Zabbix дають величезні можливості, але за них доводиться платити своїм часом, оскільки потрібно розбиратися з налаштуванням, зберіганням метрик, сповіщеннями, дашбоардами тощо. Плюс, іноді для моніторингу необхідно виділяти окремий сервер.
І як ви розумієте, для невеликого проєкту такий підхід, очевидно, є надмірним.
Саме в таких випадках Netdata виглядає досить практичним рішенням, оскільки її встановлення займає всього кілька хвилин, після чого система відразу починає збирати сотні метрик і показувати їх у зручному веб-інтерфейсі практично в реальному часі. І все це досить легке, щоб поміститися навіть на найпростішому сервері та не споживати багато ресурсів.
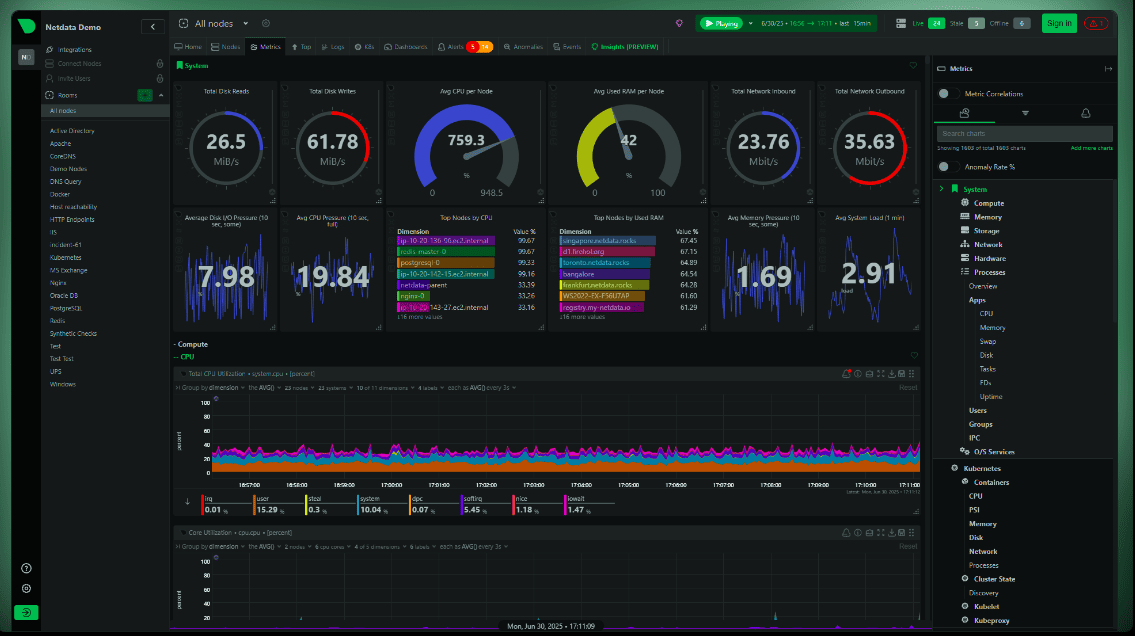
Що таке Netdata
Netdata - це система моніторингу з відкритим вихідним кодом, призначена для аналізу стану серверів, віртуальних машин, контейнерів і додатків у режимі реального часу.
Після встановлення вона автоматично виявляє більшість компонентів системи і починає збирати дані без необхідності вручну створювати дашборди, налаштовувати експортери або писати правила збору метрик. Фактично Netdata перетворює VPS на прозору систему, де можна побачити практично все, що відбувається на сервері, через єдиний веб-інтерфейс. Замість десятків консольних команд адміністратор отримує набір інтерактивних графіків, що дозволяють швидко визначити джерело проблеми.
Головна відмінність Netdata від багатьох інших платформ моніторингу полягає в орієнтації на оперативну діагностику. Якщо Grafana і Prometheus часто використовуються для аналізу тенденцій за місяці та роки, то Netdata допомагає швидко відповісти на питання: що відбувається з сервером прямо зараз і що відбувалося кілька хвилин тому.
Скільки ресурсів споживає Netdata
Одне з найчастіших запитань, яке задають перед встановленням тієї чи іншої системи моніторингу, це питання, чи не стане система моніторингу сама причиною додаткового навантаження. І ось, як ми згадали вище, Netdata вважається досить легким рішенням.
У випадку з Netdata такі побоювання зазвичай не підтверджуються, оскільки проект спочатку розроблявся з прицілом на постійний збір великої кількості метрик без помітного впливу на роботу сервера. Для цього більша частина даних обробляється локально, без складних запитів до зовнішніх баз даних і без необхідності постійно передавати великі обсяги інформації на окремий сервер моніторингу.
Ще одна причина низького споживання ресурсів полягає в архітектурі самого рішення. Netdata отримує метрики безпосередньо з операційної системи та додатків, зберігає більшу частину оперативних даних у пам'яті та оптимізована для роботи в режимі реального часу. Завдяки цьому системі не доводиться виконувати важкі обчислення або постійно звертатися до диска.
Для типового VPS можна орієнтуватися на такі показники:
| Ресурс |
Орієнтовне споживання |
| CPU |
Менше 1-2% |
| Оперативна пам’ять |
100-300 МБ |
| Дисковий простір |
Залежить від налаштувань зберігання |
| Мережевий трафік |
Мінімальний |
Звичайно, конкретні цифри залежать від кількості метрик, що збираються, кількості контейнерів, баз даних та інших сервісів на сервері. Наприклад, якщо на VPS працює кілька десятків Docker-контейнерів, то навантаження, очевидно, буде трохи вищим. А якщо це невеликий веб-сервер із простим сайтом і базою даних, тоді - істотно нижчим.
Причому бувають випадки, коли адміністратори встановлюють Netdata навіть на віртуальні машини з 1-2 ГБ оперативної пам'яті і не помічають будь-якого впливу на продуктивність. Мабуть, саме тому цей інструмент часто використовують не тільки на великих серверах, але й на невеликих VPS, де кожен мегабайт ресурсів має значення.
Які показники можна відстежувати
Відразу після встановлення Netdata починає збирати велику кількість метрик автоматично. Жодного початкового налаштування зазвичай не потрібно, адже система сама виявляє доступні пристрої, служби та додатки, а потім починає відображати дані у веб-інтерфейсі.
Набір доступних показників виходить досить значним і містить такі метрики:
- Завантаження процесора - загальне навантаження на CPU, розподіл по ядрах, системний і користувацький час, очікування вводу-виводу;
- Використання оперативної пам'яті - зайнята і вільна пам'ять, кешування, буфери, розподіл пам'яті між процесами;
- Робота swap - обсяг використовуваного swap-розділу та інтенсивність звернення до нього. Корисно при пошуку нестачі оперативної пам'яті;
- Швидкість читання та запису дисків - поточне навантаження на накопичувачі, кількість операцій вводу-виводу та затримки доступу до дисків;
- Мережевий трафік - вхідний та вихідний потік даних, навантаження на мережеві інтерфейси, обсяг переданої інформації;
- Кількість з'єднань - активні TCP- та UDP-сесії, стан мережевих підключень та навантаження на мережевий стек;
- Активність процесів - які програми споживають процесорний час та пам'ять у даний момент;
- Завантаження файлової системи - використання дискового простору за розділами та точками монтування;
- Показники Docker-контейнерів - споживання ресурсів кожним контейнером, мережевий трафік та активність процесів усередині контейнерів;
- Статистика веб-серверів - дані від Nginx, Apache та інших підтримуваних серверів за наявності відповідних модулів;
- Показники баз даних - активність MySQL, MariaDB, PostgreSQL, Redis та інших популярних СУБД.
Але на цьому список не закінчується. Наприклад, Netdata вміє показувати температуру обладнання (якщо датчики доступні системі), статистику RAID-масивів, стан служб systemd, дані віртуалізації та безліч інших параметрів.
У результаті адміністратор отримує не окремі цифри з різних утиліт, а єдину картину того, що відбувається на сервері. Іноді цього достатньо, щоб за кілька хвилин знайти причину проблем, на пошук якої через консоль довелося б витратити значно більше часу.
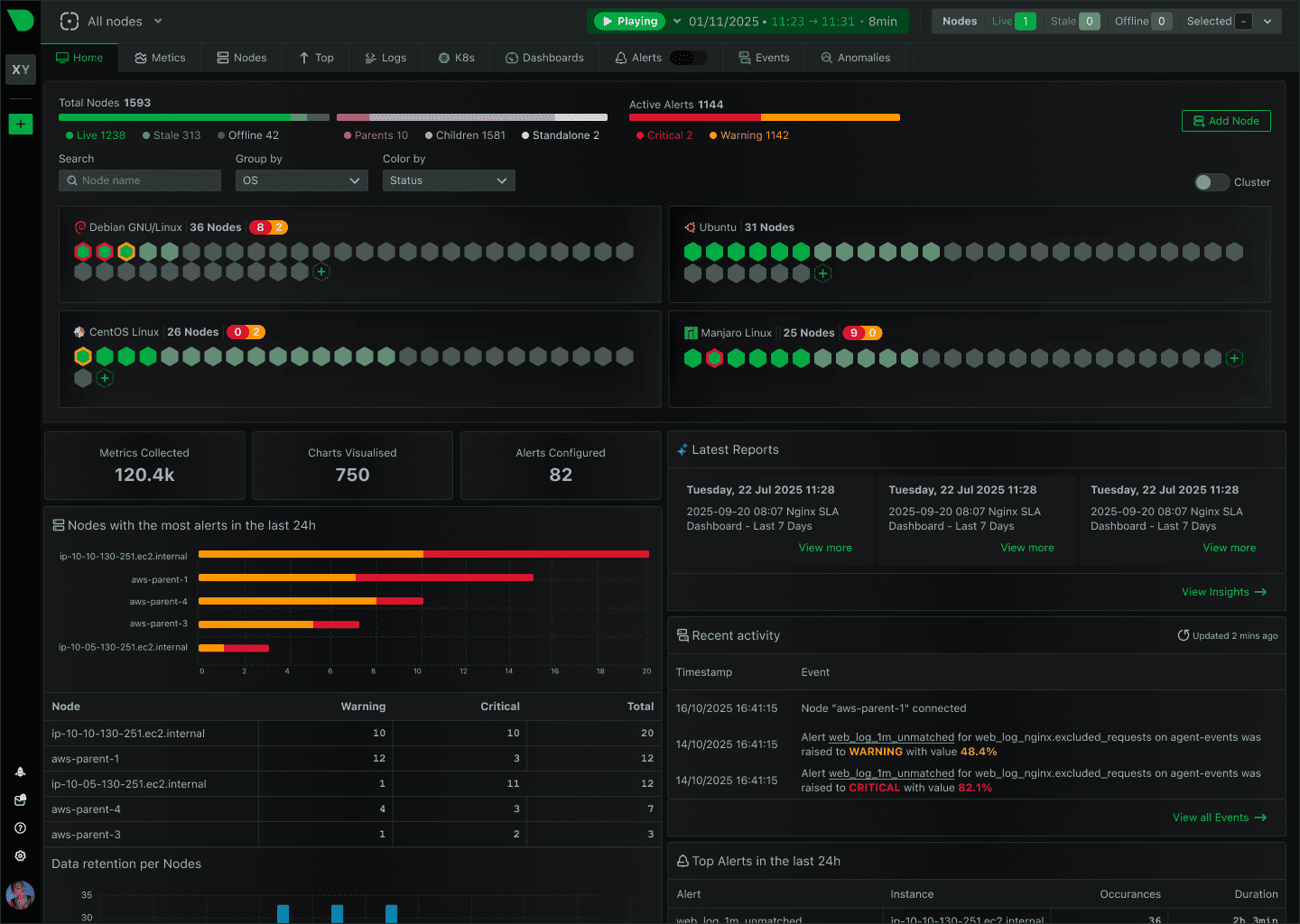
Встановлення на Linux-сервер
Одна з причин популярності Netdata - це дуже простий процес встановлення. Якщо багато систем моніторингу вимагають підготовки бази даних, налаштування агентів та ручного створення дашбордів, то тут все значно простіше.
Для більшості сучасних дистрибутивів Linux достатньо виконати офіційний скрипт встановлення:
wget -O /tmp/netdata-kickstart.sh https://get.netdata.cloud/kickstart.sh
sh /tmp/netdata-kickstart.sh
Цей скрипт самостійно визначить операційну систему, встановить необхідні залежності, завантажить актуальну версію Netdata та зареєструє службу в системі. Цей процес зазвичай займає лише кілька хвилин.
Після завершення встановлення сервіс запускається автоматично. Перевірити його стан можна командою:
systemctl status netdata
За замовчуванням веб-інтерфейс стає доступним на порту 19999 і перейти до нього ви можете, наприклад, так:
http://IP_СЕРВЕРА:19999
Однак, якщо між вами та сервером знаходиться брандмауер, то цей порт може знадобитися відкрити окремо. В іншому випадку браузер просто не зможе підключитися до інтерфейсу моніторингу.
На цьому етапі багато адміністраторів припускаються типової помилки - просто відкривають порт 19999 для всього інтернету і залишають його в такому вигляді. Так, для тестів і на час налаштування це може здатися зручним рішенням, але в робочому середовищі так робити не варто ніколи!
Все-таки це адміністративний інтерфейс сервера, і будь-який додатковий сервіс, доступний ззовні, збільшує поверхню можливої атаки. Тому навіть якщо в самому Netdata немає відомих проблем безпеки, то доброю практикою, все-таки, вважається обмеження доступу до всіх службових панелей.
Зазвичай використовують один із таких варіантів:
- доступ лише з довірених IP-адрес через брандмауер;
- підключення через VPN;
- публікація інтерфейсу через Nginx або Apache у ролі зворотного проксі;
- додаткову HTTP-аутентифікацію перед доступом до панелі.
Звичайно, для домашнього сервера або тестової віртуальної машини це може здатися зайвою обережністю. Але для будь-якого публічного VPS з білою IP-адресою такі заходи вже належать до базової гігієни безпеки.
Відразу після першого запуску Netdata починає збирати метрики. Ніяких додаткових агентів, ручного підключення пристроїв або створення графіків не потрібно. Через кілька секунд після відкриття веб-інтерфейсу вже можна побачити завантаження процесора, використання пам'яті, мережеву активність та інші показники сервера в режимі реального часу.
Ну хіба це не диво? :)
Публікація Netdata через Nginx
Якщо моніторингом потрібно користуватися регулярно, то відкривати порт 19999 безпосередньо зазвичай немає сенсу. Набагато зручніше і безпечніше опублікувати інтерфейс через Nginx і використовувати звичне доменне ім'я.
Заодно відпадає необхідність тримати додатковий порт доступним ззовні. Користувач працюватиме з Netdata через стандартний HTTP або HTTPS, а сам сервіс залишиться доступним лише локально на сервері.
Найпростіша конфігурація Nginx для публікації Netdata виглядає так:
location /netdata/ {
proxy_pass http://127.0.0.1:19999/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
Після застосування конфігурації та перезавантаження Nginx інтерфейс моніторингу стане доступним за адресою типу:
https://example.com/netdata/
Такий підхід дає відразу кілька переваг. Наприклад, з'єднання можна захистити SSL-сертифікатом, використовувати існуючі правила брандмауера та централізовано керувати доступом через веб-сервер. А якщо моніторингом користуються кілька адміністраторів, то додатково можна увімкнути HTTP-аутентифікацію. У цьому випадку, перед відкриттям панелі, Nginx запитуватиме логін та пароль.
Перше знайомство з інтерфейсом
Перше відкриття Netdata у багатьох викликає приблизно однакову реакцію: занадто багато графіків.
Екран буквально заповнений діаграмами, цифрами та показниками, що спочатку збиває з пантелику, особливо якщо раніше ваш моніторинг обмежувався командами top, htop та переглядом логів у консолі сервера.
Але через кілька хвилин спокійного ознайомлення стає зрозуміло, що хаосу тут немає. Інтерфейс згрупований за категоріями, а основні показники знаходяться буквально на перших екранах.
Найчастіше адміністратори звертаються до кількох розділів:
- CPU - загальне завантаження процесора, розподіл навантаження по ядрах, системний і користувацький час;
- Memory - використання оперативної пам'яті, кешів, буферів і swap;
- Disk - швидкість читання та запису, кількість операцій вводу-виводу, затримки роботи накопичувачів;
- Network - мережевий трафік, кількість з'єднань і навантаження на інтерфейси;
- Applications - показники окремих сервісів і додатків, якщо Netdata змогла їх виявити.
Будь-який графік можна прокрутити назад і подивитися, що відбувалося кілька хвилин, годин або навіть днів тому (залежить від налаштувань зберігання даних). Якщо користувач повідомив, що сайт був недоступний о 14:17, можна відкрити цей часовий інтервал і побачити, що відбувалося на сервері саме тоді.
Власне, заради таких ситуацій моніторинг і встановлюють. Не для красивих графіків, а для можливості побачити проблему вже після того, як вона сталася.
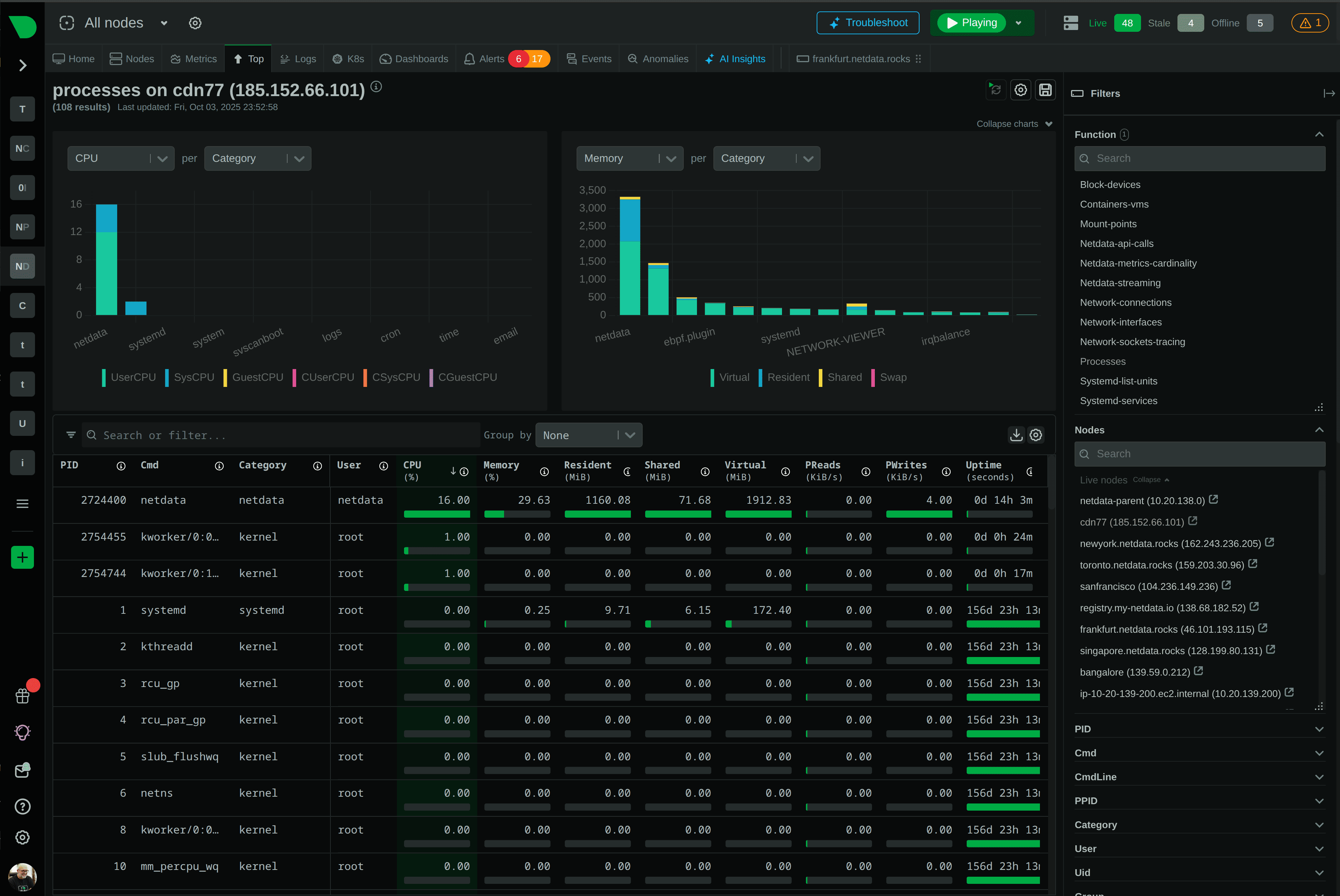
Моніторинг Docker-контейнерів і WordPress
Як ми знаємо, сьогодні все більше проєктів розробляються на основі Docker-контейнерів. Буває, що навіть відносно простий сайт може складатися з декількох окремих мікросервісів, таких як веб-сервери, бази даних, Redis, черга завдань та інших компонентів.
Netdata добре підходить для такої інфраструктури, оскільки після встановлення автоматично виявляє запущені контейнери та починає збирати статистику щодо кожного з них окремо.
Для контейнерів доступні дані про:
- завантаження процесора;
- споживання оперативної пам'яті;
- мережевий трафік;
- операції читання та запису;
- кількість процесів усередині контейнера.
Уявімо VPS, на якому WordPress працює в Docker разом з MariaDB і Redis. Користувачі починають скаржитися на повільне завантаження сторінок. Загальне навантаження сервера дійсно високе, але за звичайними системними метриками не завжди зрозуміло, який саме сервіс створює проблему.
Netdata дозволяє переглянути навантаження по кожному контейнеру окремо. Іноді виявляється, що вся проблема пов'язана з базою даних. В іншій ситуації різко зросло споживання пам'яті контейнером PHP-FPM. Буває й так, що вузьким місцем стає Redis або дискова підсистема. І все це розмаїття чудово видно на одній простій панелі.
Для WordPress такі сценарії трапляються досить часто. Наприклад, після публікації популярної статті на вашому сайті, запуску рекламної кампанії або потрапляння матеріалу в рекомендації пошукових систем - відвідуваність сайту може різко збільшитися.
І саме в такій ситуації зазвичай починають проявлятися обмеження сервера:
- закінчується вільна оперативна пам'ять;
- зростає навантаження на MySQL або MariaDB;
- збільшується кількість PHP-процесів;
- зростає навантаження на диски;
- з’являються затримки при обробці запитів.
Намагатися аналізувати такі ситуації за допомогою набору консольних утиліт не завжди зручно, особливо якщо проблема вже зникла до моменту підключення до сервера через SSH.
У Netdata всі основні показники відображаються одночасно на одному екрані. Можна швидко переглянути історію навантаження, побачити, який контейнер споживав ресурси в момент збою, і зрозуміти, чи вистачає поточної конфігурації VPS для існуючої відвідуваності. З цієї причини Netdata часто використовують не тільки для пошуку несправностей, але й для планування подальшого зростання проєкту. Коли ресурсів починає не вистачати, це стає помітно задовго до того, як сервер почне відмовляти користувачам. Втім, це одне з найважливіших завдань будь-якого моніторингу.
Повідомлення про проблеми
Навіть найдетальніший моніторинг марний, якщо адміністратор помічає проблему через кілька годин після її появи. Але ж ніхто не буде постійно тримати вкладку Netdata відкритою. Особливо якщо серверів кілька, а моніторинг використовується скоріше для контролю стану інфраструктури, ніж для безперервного спостереження за графіками.
Тому в Netdata передбачена система автоматичних повідомлень. Сервіс вміє відстежувати різні відхилення від нормальної роботи та надсилати повідомлення при виникненні проблем, наприклад, якщо процесор якийсь час працює під високим навантаженням, закінчується оперативна пам'ять на сервері або файлова система наближається до заповнення.
Підтримується кілька способів доставки повідомлень:
- Email;
- Telegram;
- Discord;
- Slack;
- Webhook та інші інтеграції.
Це особливо зручно для невеликих проєктів, де немає цілодобової команди адміністраторів. Тому замість постійної перевірки графіків система сама повідомляє про проблему, що виникла.
Для багатьох власників VPS саме сповіщення стають найкориснішою частиною системи моніторингу, адже самі графіки допомагають розібратися в причинах збою, а ось сповіщення дозволяють дізнатися про нього вчасно.
Вибір між Netdata, Prometheus і Zabbix
Питання вибору системи моніторингу виникає майже у кожного адміністратора після першого серйозного збою на сервері. Відповідь тут залежить не стільки від можливостей конкретного продукту, скільки від розмірів інфраструктури та завдань, які належить вирішувати.
Нижче наведено загальне, спрощене порівняння популярних рішень:
| Можливість |
Netdata |
Prometheus + Grafana |
Zabbix |
| Просте встановлення |
Так |
Ні |
Ні |
| Швидкий старт |
Так |
Ні |
Частково |
| Довгострокове зберігання даних |
Обмежено |
Так |
Так |
| Моніторинг одного VPS |
Відмінно |
Надлишково |
Надлишково |
| Підтримка Kubernetes |
Базова |
Відмінно |
Добре |
| Складні дашборди |
Обмежено |
Відмінно |
Добре |
| Масштабування на десятки серверів |
Частково |
Відмінно |
Відмінно |
Якщо завдання полягає в моніторингу одного VPS, декількох сайтів або невеликого набору серверів, то Netdata часто виявляється найшвидшим способом отримати корисний результат. Встановлення займає лічені хвилини, а графіки з'являються практично відразу.
З Prometheus ситуація інша. Це потужна платформа для зберігання та обробки метрик, яка особливо добре показує себе у великих інфраструктурах, Kubernetes-кластерах та середовищах з десятками або сотнями сервісів. Але разом із гнучкістю з’являється й складність. Потрібно налаштовувати збір даних, зберігання метрик, візуалізацію, правила сповіщень.
Zabbix знаходиться десь посередині. Він вміє дуже багато, добре підходить для корпоративних мереж і великих інфраструктур, але вимагає значно більше часу на початкове впровадження порівняно з Netdata.
Є ще один момент, який рідко обговорюють у порівняльних оглядах. Коли сервер починає працювати нестабільно, адміністратору часто потрібна відповідь прямо зараз. Не через звіти, не через складні запити до бази метрик, а буквально протягом декількох секунд. Відкрити сторінку і побачити, що відбувалося з процесором, пам'яттю або дисками в момент збою. І ось саме в таких ситуаціях Netdata показує себе особливо добре.
Коли Netdata вже недостатньо
При всіх своїх перевагах Netdata все ж залишається інструментом, орієнтованим насамперед на окремі сервери та оперативну діагностику.
Однак якщо ваша інфраструктура складається з десятків машин, декількох Kubernetes-кластерів, безлічі мікросервісів і вимагає зберігання метрик протягом місяців або років, то, мабуть, можливостей Netdata може виявитися недостатньо.
У таких проєктах зазвичай використовують Prometheus, Grafana, VictoriaMetrics, Zabbix та інші спеціалізовані платформи. Вони краще підходять для централізованого збору даних, складної аналітики та довгострокового зберігання історії.
Цікаво, що перехід на більшу систему моніторингу далеко не завжди означає відмову від Netdata. У багатьох компаніях вона продовжує працювати паралельно. Глобальний моніторинг ведеться через Prometheus або Zabbix, а Netdata використовується безпосередньо на серверах для швидкого аналізу проблем у режимі реального часу.
Поширені запитання
Чи підходить Netdata для VPS з 1 ГБ пам'яті?
Так, встановити його можна навіть на такий сервер. Однак потрібно пам'ятати, що сам моніторинг теж споживає ресурси. І якщо на VPS вже працює база даних, веб-сервер і кілька додатків, додаткове споживання пам'яті може виявитися помітним. Для більш комфортної роботи зазвичай рекомендують сервери з 2 ГБ RAM і вище.
Чи можна використовувати Netdata безкоштовно?
Так. Базової версії достатньо для більшості завдань, пов'язаних з моніторингом VPS, Docker-контейнерів, веб-серверів і баз даних. Для невеликих проєктів її можливостей зазвичай вистачає з запасом.
Чи працює Netdata з Docker?
Так. Після встановлення система автоматично виявляє запущені контейнери та починає збирати статистику щодо кожного з них. Окреме налаштування в більшості випадків не потрібне.
Чи можна отримувати сповіщення в Telegram?
Так. Telegram входить до списку підтримуваних каналів доставки сповіщень. Окрім нього доступні Email, Discord, Slack, Webhook та інші варіанти інтеграції.
Чим Netdata відрізняється від Grafana?
Порівнювати ці продукти безпосередньо не зовсім коректно, оскільки завдання у них частково відрізняються. Netdata орієнтована на максимально швидкий запуск та оперативну діагностику сервера в режимі реального часу. Grafana ж частіше використовується як платформа візуалізації для даних, які збираються іншими системами моніторингу, наприклад Prometheus.
Чи можна встановити Netdata на Ubuntu 24.04?
Так. Netdata без проблем працює на сучасних версіях Ubuntu, включаючи Ubuntu 24.04 LTS. Офіційний інсталяційний скрипт самостійно визначає дистрибутив і виконує необхідні дії.
Чи можна моніторити кілька серверів одночасно?
Так. Для цього передбачені інструменти централізованого перегляду даних. Такий режим зручний, якщо в інфраструктурі кілька VPS і потрібно швидко перемикатися між ними з одного інтерфейсу.
Чи підходить Netdata для продакшн-серверів?
Так. Netdata активно використовується на робочих серверах, у тому числі в комерційних проєктах. Завдяки невисокому споживанню ресурсів її можна встановлювати як на невеликі VPS, так і на досить навантажені системи.
Чи може Netdata замінити Prometheus або Zabbix?
Для одного сервера або невеликої кількості VPS - часто може. Однак, якщо потрібен централізований моніторинг великої інфраструктури, тривале зберігання метрик і складна аналітика, то можливостей спеціалізованих платформ зазвичай більше. Все залежить від масштабу проєкту та поставлених завдань.
Висновки
Отже, проблема більшості серверів полягає не в тому, що вони ламаються занадто часто, а в тому, що причини збоїв зазвичай стають відомі вже після того, як все закінчилося. Наприклад, сайт кілька хвилин відповідав повільно, база даних раптово завантажила процесор або один із контейнерів почав споживати всю доступну пам'ять, а адміністратор підключився до сервера вже тоді, коли показники повернулися до нормальних значень.
Без моніторингу такі ситуації перетворюються на суцільні здогадки.
Netdata вирішує цю задачу досить простим способом. Встановлення займає всього кілька хвилин, після чого сервер починає зберігати історію своєї роботи та відображати її в зручному інтерфейсі. Можна побачити навантаження на процесор, використання пам'яті, активність дисків, мережевий трафік, роботу контейнерів і додатків. Причому не тільки зараз, але й у той момент, коли виникла проблема.
Для власників простих VPS це корисний інструмент не тільки для пошуку несправностей, але й для прогнозування часу майбутнього апгрейду сервера, виходячи з графіків навантаження на ті чи інші компоненти системи.
Звичайно, для великих інфраструктур з десятками серверів зазвичай використовують більш складні платформи моніторингу. Але для одного VPS, невеликого проєкту, WordPress-сайту, інтернет-магазину або власного сервера додатків - можливостей Netdata часто вистачає "з головою".
По суті, це один із найпростіших способів почати стежити за станом сервера не на відчуттях, а за реальними даними. І часто саме такий підхід допомагає виявити проблему задовго до того, як вона перетвориться на повноцінний збій.












