Ошибка HTTP 504 - это одна из тех вещей, которые одинаково бесят и пользователей, и людей по ту сторону сервера. Сайт вроде бы живой, сервер отвечает, сеть не отвалилась и даже приложение чаще всего продолжает работать. Но в какой-то момент запрос как бы "застревает" внутри инфраструктуры - и вместо запрашиваемой страницы пользователь получает холодное Gateway Timeout.
И вот что особенно неприятно, что ошибка 504 почти никогда не говорит прямо, где именно проблема. Упал ли backend, завис SQL-запрос, какой-нибудь внешний API отвечает по 40 секунд, перегрузился Nginx или Cloudflare просто не дождался ответа. Иногда причина вообще может находиться между датацентрами, а сам сайт при этом выглядит абсолютно рабочим.
Из-за этого 504 считается одной из самых мутных инфраструктурных ошибок. Код 500 хотя бы намекает, что приложение сломалось. 404 честно сообщает, что страницы нет. А тут всё выглядит "почти нормально", но в том то и дело, что именно почти.
Часто такие ошибки всплывают под высокой нагрузкой. Например интернет-магазин во время распродажи или WordPress с десятком тяжёлых плагинов. Наконец backend на Docker-контейнерах, который внезапно начал упираться в CPU или диск. Ну а бывает и куда веселее, когда один медленный запрос к базе начинает собирать очередь из остальных запросов, после чего таймауты расползаются по всей системе.
И да - ошибка 504 почти всегда является маркером проблемы, но никогда не бывает самостоятельной проблемой. Просто она означает, что где-то внутри инфраструктуры уже есть узкое место, но просто браузер видит именно timeout.
Давайте в данной статье попробуем разобраться, что происходит в момент появления HTTP 504, где такие ошибки ищут в первую очередь и как вообще диагностируют подобные зависания в нормальной инфраструктуре.
Что означает ошибка 504
HTTP 504 появляется в тот момент, когда один сервер слишком долго ждёт ответ от другого. В какой-то момент ожидание заканчивается и наружу улетает ответ Gateway Timeout.
Обычно речь идёт не о самом сайте, а о промежуточном звене, как например Nginx, Cloudflare, Load Balancer, Kubernetes Ingress или API Gateway. Фактически ведь пользователь общается именно с ними, а уже они пытаются достучаться до backend-приложения.
Схема большинства приложений чаще всего выглядит примерно так:
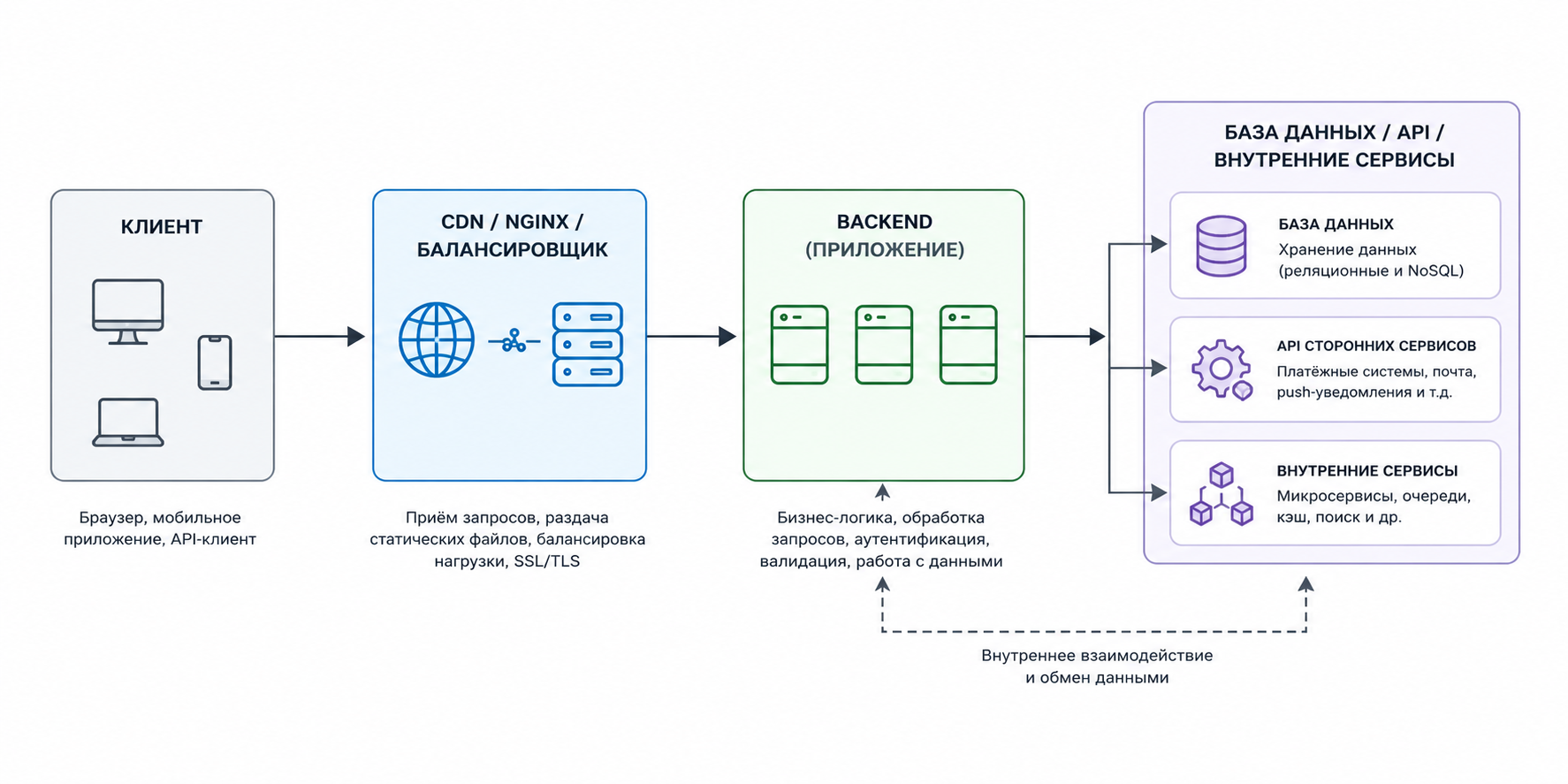
И вот тут начинается самое интересное. Пользователь видит только финальную ошибку, но настоящая причина может сидеть глубоко внутри цепочки, иногда вообще в самом неожиданном месте.
Например, Nginx отправил запрос в Gunicorn, а Python-приложение зависло на тяжёлом SQL-запросе. Или Cloudflare честно ждёт origin-сервер, который в этот момент упёрся в CPU и начал отвечать по 40 секунд. В Kubernetes похожая история бывает с Pod’ами, когда Ingress работает нормально, контейнеры живы, readiness checks зелёные, а один сервис внутри всё равно тормозит всю цепочку.
Отдельная категория боли - это внешние API, особенно платёжные шлюзы, всякие CRM и прочие вещи, которые разработчик не контролирует напрямую. Один медленный запрос наружу и timeout начинает расползаться дальше по инфраструктуре.
В итоге фронтовой сервер просто перестаёт ждать. Не потому что "всё упало", а потому что просто вышло время ожидания.
Поэтому диагностика 504 ошибки редко ограничивается проверкой одного Nginx-конфига и смотреть приходится на всё сразу: backend, базу данных, Docker-контейнеры, сеть между нодами, очереди задач, Redis, внешние API и чёрт знает что ещё. Ну и часто бывает, что проблема обнаруживается там, где её вообще не ждали - например в DNS-запросах или медленном сетевом хранилище.
Как выглядит ошибка 504 в разных системах
Ошибка HTTP 504 далеко не всегда выглядит одинаково. Всё зависит от того, кто именно первым "сдался" в цепочке ожидания, так как один и тот же зависший backend может вызывать совершенно разные сообщения, что регулярно сбивает с толку даже опытных администраторов.
Вот типичные варианты:
| Система |
Как выглядит ошибка |
| Nginx |
504 Gateway Timeout |
| Cloudflare |
Error 504 |
| Kubernetes Ingress |
upstream request timeout |
| AWS Load Balancer |
Gateway Timeout |
| PHP-FPM |
upstream timed out |
| Gunicorn |
WORKER TIMEOUT |
Снова не будет лишним повторить, что компонент, который показывает ошибку, совсем не обязан быть источником сбоя, он просто оказался первым в цепочке, кто перестал ждать ответ.
Например, Cloudflare показывает Error 504 - значит виноват CDN. Логично? Логично. Только проблема может сидеть вообще в PostgreSQL, который отвечает 25 секунд на один запрос.
С Kubernetes это особенно весело. DevOps увеличивает timeout в Ingress, ошибка на время исчезает и все довольны... Но не долго, так как через неделю сайт снова начинает тормозить. А всё потому, что контейнеры всё это время упирались в диск или в CPU, а timeout просто маскировал реальную проблему.
Вообще 504 часто работает как сигнал типа "где закончилось терпение" - не более того.
Основные причины ошибки 504
Как мы уже выяснили, хоть ошибка HTTP 504 почти всегда выглядит одинаково, но причин у её появления может быть масса. Иногда всё действительно упирается в банальный timeout в Nginx. Но чаще всего HTTP 504 - это уже финальный симптом того, что внутри инфраструктуры какой-то из компонентов давно работает на грани, просто наружу это вылезло только сейчас.
Есть несколько сценариев, которые встречаются постоянно.
Медленный backend
Самая частая причина - backend слишком долго обрабатывает запрос.
И проблема тут далеко не всегда в слабом сервере. Даже нормальная инфраструктура может начать ловить 504 ошибку, если приложение делает что-то тяжёлое прямо во время HTTP-запроса, например делает экспорт в Excel.
Перечислим типичные ситуации:
- тяжёлый SQL-запрос;
- обращение к внешнему API;
- генерация PDF или архива на лету;
- синхронная обработка больших объёмов данных;
- нехватка CPU или RAM.
Иногда всё работает месяцами без единой ошибки, а потом пользователи внезапно начинают массово выгружать годовые отчёты. В итоге Gunicorn worker зависает секунд на 40-50, очередь растёт, Nginx перестаёт дожидаться ответа и привет ошибка 504.
С платёжными API похожая история. Пользователь нажал кнопку оплаты, backend ушёл к внешнему сервису, тот отвечает слишком долго. Получается, что сайт формально жив, но клиент уже смотрит на заглушку Gateway Timeout.
Таймауты на уровне прокси
Бывает и другая ситуация, когда backend успевает обработать запрос, но прокси просто не хочет ждать так долго.
У Nginx, Cloudflare, API Gateway, различных балансировщиков - у всех есть собственные предустановленные лимиты ожидания. И если backend работает немного дольше, чем ожидалось, то соединение обрывается раньше времени.
В Nginx за это обычно отвечают инструкции как:
proxy_read_timeoutfastcgi_read_timeoutproxy_connect_timeoutproxy_send_timeout
Допустим, приложение отвечает за 70 секунд, а proxy_read_timeout выставлен в 60. Это означает, что на 61-й секунде Nginx вернёт 504, даже если backend уже почти закончил работу.
Из-за этого многие начинают бесконечно повышать timeout. Иногда это действительно помогает, но чаще просто делает зависания ещё длиннее и мучительнее. Бороться нужно с причиной таймаута.
Сетевые проблемы
HTTP 504 легко появляется даже в приложениях, написанных абсолютно без ошибок в коде или инфраструктуре.
Особенно часто это случается в инфраструктурах, где архитектурно имеется куча промежуточных звеньев, таких как CDN, Kubernetes, VPN, несколько датацентров, внешние API, микросервисы и т.д. и т.п. В таких условиях достаточно небольшой сетевой деградации, как таймауты начинают сыпаться пачками.
Причины бывают очень разные, так как сети - это отдельная большая тема. Но самыми частыми причинами появления 504 ошибки являются:
- потеря пакетов;
- перегруженный uplink;
- нестабильная маршрутизация;
- firewall rules;
- проблемы peering между провайдерами;
- ограничения со стороны CDN.
Бесит, что внешне сервер может выглядеть полностью рабочим, SSH открывается, ping идёт. А HTTP-запросы периодически висят по 20-30 секунд и в конце концов уходят в timeout. Поэтому фраза "сервер же пингуется" почти никогда ничего не доказывает.
Перегрузка сервера
Пожалуй самая банальная причина - это когда серверу плохо, когда он ещё не умер окончательно, но уже задыхается под нагрузкой. CPU висит под 100%, памяти почти нет, swap начинает молотить диск, I/O wait растёт, а в итоге backend перестаёт успевать обрабатывать запросы.
На VPS это обычно ощущается довольно характерно - сайт начинает открываться через раз или SSH начинает как бы подвисать.
Swap - это отдельная боль, так как когда Linux начинает активно выгружать память на диск, то backend может замедлиться в разы, особенно на дешёвых VPS с медленным storage. Снова таки, формально приложение продолжает работать, но в реальности инфраструктура уже не справляется.
Проблемы с базой данных
Одна из самых недооценённых причин появления ошибки 504 - это база данных.
Причём backend при этом может быть полностью исправен и вообще ни в коде ни в архитектуре проекта ничего не менялось. Просто PostgreSQL или MySQL внезапно начинают отвечать гораздо дольше, чем раньше.
В таком ходе развития событий обычно виноваты такие причины как:
- отсутствие индексов;
- тяжёлые JOIN;
- блокировки таблиц;
- неэффективный SQL от ORM;
- переполненный connection pool.
DDoS, боты и всплески трафика
Наконец бывают случаи, когда иногда инфраструктура ломается не изнутри, а снаружи. Причём это далеко не всегда полноценный DDoS. Хватает нескольких агрессивных ботов, crawler storm или внезапного наплыва пользователей после поста на Reddit или в соцсетях.
В какой-то момент сервер упирается в лимиты:
- заканчиваются worker connections;
- backend не успевает держать keepalive-соединения;
- растёт очередь запросов;
- CPU и память уходят в потолок;
- часть запросов начинает получать timeout.
Как вы видите, в этом случае сразу всплывают несколько симптомов, описанных в предыдущих подразделах.
На небольших VPS это может быть особенно заметно. Достаточно пары сотен одновременных соединений и приложение уже начинает вести себя так, будто его атакуют, хотя формально трафик может быть вполне "легальным".
Диагностика ошибки HTTP 504
Самой частой ошибкой администраторов при появлении кода HTTP 504 является паника. Администратор начинает крутить таймауты, перезапускать контейнеры и переписывать конфиги вслепую. Иногда это даже помогает, но увы либо не надолго, либо вовсе может привести систему к более масштабному сбою.
Мы уже знаем, что ошибка 504 почти никогда не показывает источник проблемы напрямую. Ошибка всплывает в одном месте, а настоящая причина может сидеть вообще в другом слое инфраструктуры. Поэтому важнейшей задачей становится именно диагностика и локализация проблемы.
Ниже мы привели базовый сценарий диагностики, который применим для большинства инфраструктур, так как все современные приложения и системы строятся приблизительно одинаково и с использованием одних и тех-же составляющих.
Проверка логов веб-сервера
Всегда стоит начинать диагностику с просмотра логов и лучше с логов reverse proxy, чаще всего это Nginx. Именно там обычно появляется первая нормальная подсказка, которая может указать на действительную причину проблемы.
Для начала смотрим лог ошибок:
tail -f /var/log/nginx/error.log
Очень часто там всплывает что-то вроде:
upstream timed out (110: Connection timed out)
Это уже отличная зацепка из которой мы видим, что Nginx не смог дождаться ответа от backend.
Потом стоит посмотреть и access.log:
tail -f /var/log/nginx/access.log
Особенно интересны нам будут поля вроде request_time и upstream_response_time. Если они внезапно начинают расти с миллисекунд до десятков секунд, то проблема почти наверняка уже внутри backend или базы данных.
Иногда этого хватает, чтобы сразу понять направление поиска. Особенно когда видно, что timeout возникает только на конкретных URL или API-методах.
Обращение к backend напрямую
Следующим разумным шагом будет убрать из цепочки proxy и проверить само приложение напрямую. То есть не через Nginx, Cloudflare или балансировщик, а сразу в backend. Это удобно делать с помощью простого curl-запроса:
Например:
curl http://127.0.0.1:8000
или:
curl http://backend_container:3000
Если напрямую backend отвечает быстро, а через proxy появляется ошибка 504, значит очевидно, что проблема где-то между ними, например timeout, сеть, proxy-настройки, CDN или балансировщик.
Если же backend зависает даже напрямую, тогда копать нужно уже внутри приложения.
Кстати, при работе через Cloudflare есть один нюанс. Иногда полезно временно отключить proxy-режим и сходить напрямую на origin-сервер. Это быстро показывает, связана ли проблема с CDN или сервер сам не справляется.
Проверка состояния backend
Если проблема всё же с самим backend-сервером, тогда будем детальнее разбираться конкретно с ним.
Неважно, что вы используете: Gunicorn, Node.js, PHP-FPM, uWSGI или Java-сервисы - логика всегда примерно одинаковая. Для начала нужно понять, сервер перегружен или нет, т.е. начинаем с проверки буквально самого железа.
Обычно начинают с таких команд как:
top
или:
htop
Смотреть нам нужно вот на что:
- load average;
- использование RAM;
- swap;
- I/O wait;
- количество backend-процессов;
- зависшие worker'ы.
Как мы уже упоминали выше - swap тут особенно показателен, так как если Linux начал активно выгружать память на диск, то производительность может критически проседать даже без полного падения сервера.
Проверка базы данных
Так как практически ни одно приложение или сайт не обходятся без базы данных, то стоит проверить и её, так как часто причиной проблемы может послужить именно она.
В PostgreSQL обычно первым делом смотрят:
SELECT * FROM pg_stat_activity;
Особенно подозрительно выглядят:
- long-running queries;
- блокировки;
idle in transaction;- тяжёлые JOIN;
- sequential scan;
- огромный execution time.
Проверка сети
Ну и наконец, иногда backend может быть полностью исправен, как и база данных. А проблема заключается в сети. Поэтому сеть мы тоже всегда диагностируем.
Для начала обычно проверяют:
ping
traceroute
mtr
Потом уже смотрят на firewall rules, security groups, NAT, VPN, CDN routing, MTU. Да-да, MTU тоже иногда ломает жизнь администратора совершенно абсурдным образом.
Как исправить ошибку HTTP 504
Способ исправления HTTP 504 всегда зависит от того, где именно была локализована проблема. Иногда хватает одной правки в timeout, а иногда выясняется, что backend уже давно работает на пределе, просто проблема наконец стала заметна пользователям.
К сожелению нет никакой "волшебной таблетки", чтобы "полечить" ошибку 504, особенно если инфраструктура уже перегружена. Поэтому давайте пройдёмся по нескольким вещам, которые могут быть полезны в этом случае.
Увеличение timeout
Первое, что обычно делают при появлении ошибки 504 - это увеличение timeout.
Ну и иногда это действительно оправдано, в частности, если backend выполняет тяжёлую, но корректную задачу, например собирает большой Excel-отчёт, генерирует большой архив, рендерит видео или считает сложную аналитику.
В Nginx обычно смотрят на эти инструкции в файле конфигурации:
proxy_read_timeout 120;
proxy_connect_timeout 60;
proxy_send_timeout 120;
Для PHP-FPM:
request_terminate_timeout = 120
Но проблема в том, что timeout очень легко превратить в костыль, о чем мы говорили немного выше.
Если backend уже задыхается под нагрузкой, то увеличение времени ожидания просто заставляет пользователя смотреть на загрузку дольше. Более того, медленные запросы продолжают держать занятыми worker’ы, очередь растёт, а сервер начинает рассыпаться ещё быстрее.
Поэтому увеличение timeout - это скорее временная мера, которая иногда может оказать пользу, но во многих сулчаев может сослужить и недобную службу. Но по крайней мере об этой опции стоит знать.
Оптимизация backend
В реальных production-системах именно backend чаще всего оказывается главным источником 504 и причиной тому является попытка приложения выполнить слишком много тяжёлой работы внутри одного HTTP-запроса.
Примерами таких работ могут служить классические:
- генерация PDF или Excel;
- экспорт больших таблиц;
- тяжёлые SQL-запросы;
- обработка изображений;
- синхронные вызовы внешних API.
И пока backend всем этим занимается, worker остаётся занятым, в результате чего новые запросы копятся в очереди. Ну и со временем timeout начинает распространяться по всей системе.
В таких случаях обычно помогает:
- вынос тяжёлых задач в очередь;
- Celery, RQ, BullMQ и подобные системы;
- оптимизация SQL;
- добавление индексов;
- Redis-кеширование;
- pagination;
- уменьшение количества ORM-запросов;
- отказ от синхронных API-вызовов.
- и т.д. и т.п.
Например, вместо генерации PDF прямо внутри запроса backend может просто создать задачу в очереди и сразу вернуть пользователю статус обработки. Документ сформируется отдельно, без блокировки worker’ов.
После таких изменений приложение обычно начинает работать не только быстрее, но и гораздо стабильнее под нагрузкой.
Масштабирование инфраструктуры
Иногда проблема всё-таки заключается в ресурсах самого севера. Особенно часто это случается на VPS, которые месяцами работают на пределе выделенных ресурсов, пока однажды не приходит чуть больше трафика, чем обычно. После этого начинаются random timeout’ы, подвисания SSH и странные лаги во всей системе.
В таких случаях помогает, (ваш кэп):
- добавить CPU;
- увеличить RAM;
- перейти на NVMe;
- распределить backend по нескольким инстансам;
- поставить балансировщик нагрузки.
Больше эту тему обсуждать не видим смысла, так как тут всё и так очевидно.
Настройка keepalive и лимитов соединений
Бывает и так, что CPU свободен, база данных живая, а timeout всё равно появляется. В таком случае, причина может крыться в сетевых соединениях, когда, например, backend не справляется с большим количеством keepalive-сессий или Nginx упирается в лимиты worker_connections.
Обычно в этом случае проверяют такие инструкции как:
keepalive_timeout 65;
и:
worker_connections 4096;
Потом уже смотрят системные лимиты:
ulimit -n
Если серверу не хватает файловых дескрипторов, то новые подключения начинают зависать совершенно хаотично. Особенно неприятно это выглядит во время crawler storm или L7 DDoS, когда сервер вроде бы жив, но часть запросов внезапно уходит в timeout.
Какие метрики мониторить, чтобы предотвратить 504
До какого-то момента мы считали, что необходимость мониторинга систем понятна всем и это аксиома. Ведь в большинстве случаев HTTP 504 не появляется внезапно и обычно перед этим система начинает постепенно деградировать. Но оказывается, что на практике очень много проектов пренебрегают мониторингом. Особенно этим страдают т.н. "вайбкодеры" в своих "вайбкод-проектах", которые даже не задумываются над этим вопросом.
Запомните, мониторинг - это один из самых важных инструментов для предотвращения любых проблем в системе, в том числе и HTTP 504 Gateway Timeout. Он позволяет заметить проблему ещё до того, как пользователи начнут видеть ошибки и сообщать вам об этом в тикетах или в письмах.
Для production-инфраструктуры обычно мониторят следующие показатели:
| Что мониторить |
Почему важно |
Инструменты |
| CPU Load |
backend не успевает обрабатывать запросы |
Prometheus, Netdata, Grafana |
| RAM и Swap |
нехватка памяти резко замедляет backend |
Netdata, node_exporter |
| Disk I/O |
база данных и backend ждут диск |
iostat, Prometheus |
| Request Latency |
растёт время ответа приложения |
Grafana, OpenTelemetry |
| SQL Query Time |
медленные запросы тормозят backend |
PostgreSQL Exporter, pg_stat_activity |
| Active Connections |
сервер перегружается соединениями |
Nginx Exporter, Netstat |
| Error Rate |
backend начинает чаще отдавать ошибки |
Sentry, Loki |
| Queue Size |
фоновые задачи не успевают обрабатываться |
Celery Exporter, BullMQ metrics |
В небольших проектах часто хватает связки Netdata + Grafana, а в более сложных инфраструктурах обычно используют Prometheus, Loki и OpenTelemetry. Но всё это "на любителя" и конкретный стек конечно зависит от ваших потребностей, задач и ваших личных навыков как администратора.
FAQ: HTTP 504 Gateway Timeout
Чем отличается 504 от 502?
502 Bad Gateway означает, что backend вернул некорректный ответ. А 504 Gateway Timeout - означает, что backend не успел ответить вовремя.
Может ли база данных вызывать 504?
Да. Это одна из самых частых причин, так как долгие SQL-запросы и блокировки быстро приводят к timeout backend.
Помогает ли увеличение proxy_read_timeout?
Иногда - да, но если backend перегружен, то это является лишь временной мерой.
Может ли Cloudflare вызывать 504?
Иногда, но чаще Cloudflare просто показывает проблему origin-сервера.
Почему 504 появляется под нагрузкой?
Backend перестаёт успевать обрабатывать запросы из-за нехватки CPU, RAM, медленного SQL или высокого I/O wait.
Может ли Docker или Kubernetes вызывать 504?
Да, может. И тут основными причинами являются ingress timeout, перегруженный Pod, restart loop или зависший контейнер.
Вывод
HTTP 504 Gateway Timeout - это одна из тех ошибок, которые почти никогда не возникают "просто так". Обычно это уже следствие более глубокой проблемы, когда backend не справляется с нагрузкой, база данных отвечает слишком медленно, сеть начинает терять пакеты, контейнеры упираются в ресурсы или приложение выполняет слишком тяжёлые операции прямо внутри запроса.
И самое неприятное, что место появления ошибки часто вообще не совпадает с её источником.
Часто пользователь видит страницу Cloudflare, администратор наблюдает - timeout в Nginx, а backend пишет WORKER TIMEOUT в логе. А на самом деле проблема всё это время может заключаться в одном SQL-запросе, который внезапно начал выполняться по 20 секунд.
Из-за этого диагностика ошибки 504 почти всегда требует смотреть на инфраструктуру целиком.
В классической production-инфраструктуре HTTP 504 редко появляется совсем внезапно и обычно перед этим уже начинают мигать тревожные сигналы, такие как рост latency, медленные ответы SQL, увеличение load average и т.д. Просто многие замечают проблему только в тот момент, когда пользователи уже видят Gateway Timeout.
Поэтому хороший мониторинг и нормальная архитектура часто предотвращают появление ошибки 504 ещё до того, как ошибка успевает попасть в браузер.












