Помилка HTTP 504 - це одна з тих речей, які однаково дратують і користувачів, і тих, хто працює на сервері. Сайт начебто працює, сервер відповідає, мережа не відвалилася і навіть додаток найчастіше продовжує працювати. Але в якийсь момент запит ніби "застрягає" всередині інфраструктури - і замість запитуваної сторінки користувач отримує холодне Gateway Timeout.
І ось що особливо неприємно, що помилка 504 майже ніколи не говорить прямо, де саме проблема. Чи впав backend, завис SQL-запит, якийсь зовнішній API відповідає по 40 секунд, перевантажився Nginx або Cloudflare просто не дочекався відповіді. Іноді причина взагалі може знаходитися між датацентрами, а сам сайт при цьому виглядає абсолютно робочим.
Через це 504 вважається однією з найнезрозуміліших інфраструктурних помилок. Код 500 хоча б натякає, що додаток зламався. 404 чесно повідомляє, що сторінки немає. А тут все виглядає "майже нормально", але в тому-то й річ, що саме майже.
Часто такі помилки виникають під високим навантаженням. Наприклад, інтернет-магазин під час розпродажу або WordPress з десятком важких плагінів. Нарешті, backend на Docker-контейнерах, який раптово почав навантажувати CPU або диск. Ну а буває й набагато веселіше, коли один повільний запит до бази починає збирати чергу з інших запитів, після чого таймаути розповзаються по всій системі.
І так - помилка 504 майже завжди є маркером проблеми, але ніколи не буває самостійною проблемою. Просто вона означає, що десь всередині інфраструктури вже є вузьке місце, але браузер бачить саме тайм-аут.
Давайте в цій статті спробуємо розібратися, що відбувається в момент появи HTTP 504, де такі помилки шукають у першу чергу і як взагалі діагностують подібні зависання в нормальній інфраструктурі.
Що означає помилка 504
HTTP 504 з'являється в той момент, коли один сервер занадто довго чекає відповіді від іншого. У якийсь момент очікування закінчується і назовні вилітає відповідь Gateway Timeout.
Зазвичай мова йде не про сам сайт, а про проміжну ланку, як наприклад Nginx, Cloudflare, Load Balancer, Kubernetes Ingress або API Gateway. Адже фактично користувач спілкується саме з ними, а вже вони намагаються достукатися до backend-додатку.
Схема більшості додатків найчастіше виглядає приблизно так:
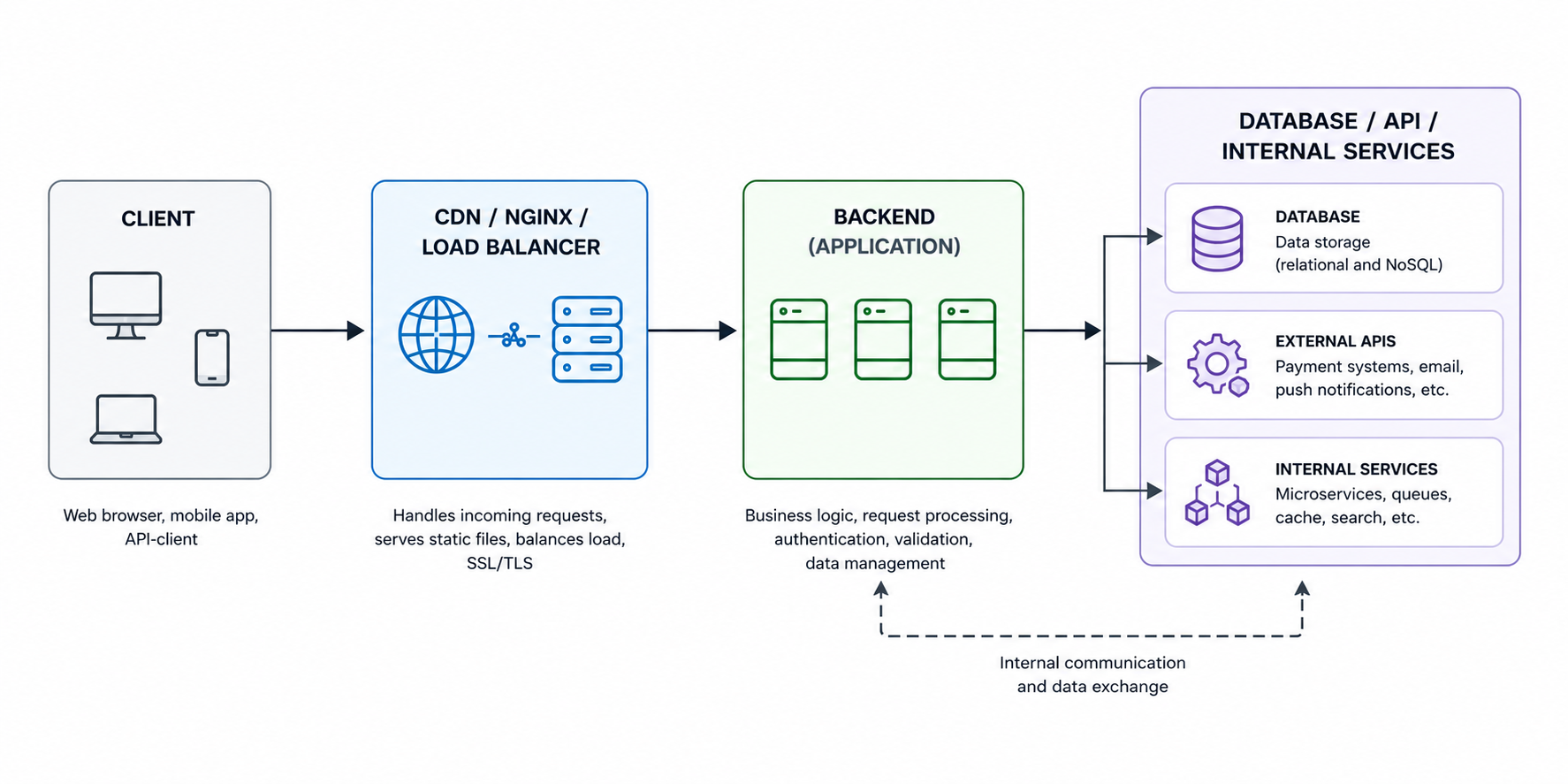
І ось тут починається найцікавіше. Користувач бачить лише фінальну помилку, але справжня причина може сидіти глибоко всередині ланцюжка, іноді взагалі в найнесподіванішому місці.
Наприклад, Nginx відправив запит у Gunicorn, а Python-додаток завис на важкому SQL-запиті. Або Cloudflare чесно чекає на origin-сервер, який у цей момент застряг у CPU і почав відповідати по 40 секунд. У Kubernetes подібна історія трапляється з Pod’ами, коли Ingress працює нормально, контейнери живі, readiness checks зелені, а один сервіс всередині все одно гальмує весь ланцюжок.
Окрема категорія болю - це зовнішні API, особливо платіжні шлюзи, всілякі CRM та інші речі, які розробник не контролює безпосередньо. Один повільний запит назовні і timeout починає розповзатися далі по інфраструктурі.
У підсумку фронтовий сервер просто перестає чекати. Не тому що "все впало", а тому що просто закінчився час очікування.
Тому діагностика помилки 504 рідко обмежується перевіркою одного Nginx-конфігу та доводиться дивитися на все одразу: backend, базу даних, Docker-контейнери, мережу між вузлами, черги завдань, Redis, зовнішні API та хтозна-що ще. Ну і часто буває, що проблема виявляється там, де її взагалі не чекали - наприклад, у DNS-запитах або повільному мережевому сховищі.
Як виглядає помилка 504 у різних системах
Помилка HTTP 504 далеко не завжди виглядає однаково. Все залежить від того, хто саме першим "здався" у ланцюжку очікування, оскільки один і той самий завислий backend може викликати абсолютно різні повідомлення, що регулярно збиває з пантелику навіть досвідчених адміністраторів.
Ось типові варіанти:
| Система |
Як виглядає помилка |
| Nginx |
504 Gateway Timeout |
| Cloudflare |
Error 504 |
| Kubernetes Ingress |
upstream request timeout |
| AWS Load Balancer |
Gateway Timeout |
| PHP-FPM |
upstream timed out |
| Gunicorn |
WORKER TIMEOUT |
Знову не буде зайвим повторити, що компонент, який показує помилку, зовсім не обов'язково є джерелом збою, він просто виявився першим у ланцюжку, хто перестав чекати відповіді.
Наприклад, Cloudflare показує Error 504 - значить, винен CDN. Логічно? Логічно. Тільки проблема може лежати взагалі в PostgreSQL, який відповідає 25 секунд на один запит.
З Kubernetes це особливо весело. DevOps збільшує timeout в Ingress, помилка на деякий час зникає і всі задоволені... Але не надовго, оскільки через тиждень сайт знову починає гальмувати. А все тому, що контейнери весь цей час натрапляли на обмеження диска або CPU, а timeout просто маскував реальну проблему.
Взагалі 504 часто працює як сигнал типу "де закінчилося терпіння" - не більше того.
Основні причини помилки 504
Як ми вже з'ясували, хоч помилка HTTP 504 майже завжди виглядає однаково, але причин її появи може бути безліч. Іноді все дійсно впирається в банальний timeout в Nginx. Але найчастіше HTTP 504 - це вже фінальний симптом того, що всередині інфраструктури якийсь із компонентів давно працює на межі, просто назовні це вилізло тільки зараз.
Є кілька сценаріїв, які зустрічаються постійно.
Повільний backend
Найчастіша причина - backend занадто довго обробляє запит.
І проблема тут далеко не завжди в слабкому сервері. Навіть нормальна інфраструктура може почати ловити помилку 504, якщо додаток робить щось важке прямо під час HTTP-запиту, наприклад, експортує дані в Excel.
Перелічимо типові ситуації: Іноді все працює місяцями без жодної помилки, а потім користувачі раптово починають масово завантажувати річні звіти. У підсумку Gunicorn worker зависає на 40-50 секунд, черга зростає, Nginx перестає чекати відповіді - і ось вам помилка 504.
- важкий SQL-запит;
- звернення до зовнішнього API;
- генерація PDF або архіву на льоту;
- синхронна обробка великих обсягів даних;
- нестача CPU або RAM.
З платіжними API схожа історія. Користувач натиснув кнопку оплати, backend звернувся до зовнішнього сервісу, той відповідає занадто довго. Виходить, що сайт формально живий, але клієнт уже бачить заглушку Gateway Timeout.
Таймаути на рівні проксі
Буває й інша ситуація, коли backend встигає обробити запит, але проксі просто не хоче чекати так довго.
У Nginx, Cloudflare, API Gateway, різних балансувальників - у всіх є власні попередньо встановлені ліміти очікування. І якщо backend працює трохи довше, ніж очікувалося, то з'єднання обривається раніше часу.
У Nginx за це зазвичай відповідають такі налаштування: Припустимо, додаток відповідає за 70 секунд, а proxy_read_timeout встановлено на 60. Це означає, що на 61-й секунді Nginx поверне 504, навіть якщо backend вже майже закінчив роботу.
proxy_read_timeoutfastcgi_read_timeoutproxy_connect_timeoutproxy_send_timeout
Через це багато хто починає нескінченно збільшувати timeout. Іноді це дійсно допомагає, але частіше просто робить зависання ще довшими та боліснішими. Боротися потрібно з причиною таймауту.
Мережеві проблеми
HTTP 504 легко з’являється навіть у додатках, написаних абсолютно без помилок у коді чи інфраструктурі.
Особливо часто це трапляється в інфраструктурах, де архітектурно є купа проміжних ланок, таких як CDN, Kubernetes, VPN, кілька датацентрів, зовнішні API, мікросервіси тощо. У таких умовах достатньо невеликої мережевої деградації, як таймаути починають сипатися пачками.
Причини бувають дуже різні, оскільки мережі - це окрема велика тема. Але найчастішими причинами появи помилки 504 є: Дратує, що зовні сервер може виглядати повністю робочим, SSH відкривається, ping працює. А HTTP-запити періодично зависають на 20-30 секунд і зрештою йдуть у timeout. Тому фраза "сервер же пінгується" майже ніколи нічого не доводить.
- втрата пакетів;
- перевантажений uplink;
- нестабільна маршрутизація;
- правила брандмауера;
- проблеми peering між провайдерами;
- обмеження з боку CDN.
Перевантаження сервера
Мабуть, найбанальніша причина - це коли серверу погано, коли він ще не помер остаточно, але вже задихається під навантаженням. CPU висить під 100%, пам'яті майже немає, swap починає молотити диск, I/O wait зростає, а в підсумку backend перестає встигати обробляти запити.
На VPS це зазвичай відчувається досить характерно - сайт починає відкриватися через раз або SSH починає ніби зависати.
Swap - це окрема проблема, оскільки коли Linux починає активно вивантажувати пам'ять на диск, то backend може сповільнитися в рази, особливо на дешевих VPS із повільним storage. Знову ж таки, формально додаток продовжує працювати, але в реальності інфраструктура вже не справляється.
Проблеми з базою даних
Одна з найбільш недооцінених причин появи помилки 504 - це база даних.
Причому backend при цьому може бути повністю справним і взагалі ні в коді, ні в архітектурі проєкту нічого не змінювалося. Просто PostgreSQL або MySQL раптово починають відповідати набагато довше, ніж раніше.
У такому перебігу подій зазвичай винні такі причини, як:
- відсутність індексів;
- важкі JOIN;
- блокування таблиць;
- неефективний SQL від ORM;
- переповнений connection pool.
DDoS, боти та сплески трафіку
Нарешті бувають випадки, коли інфраструктура ламається не зсередини, а ззовні. Причому це далеко не завжди повноцінний DDoS. Достатньо кількох агресивних ботів, crawler storm або раптового напливу користувачів після публікації на Reddit або в соцмережах.
У якийсь момент сервер досягає лімітів: Як ви бачите, у цьому випадку відразу спливають кілька симптомів, описаних у попередніх підрозділах.
- закінчуються worker connections;
- backend не встигає підтримувати keepalive-з'єднання;
- зростає черга запитів;
- CPU та пам'ять досягають межі;
- частина запитів починає отримувати timeout.
На невеликих VPS це може бути особливо помітно. Достатньо кількох сотень одночасних з'єднань, і додаток вже починає поводитися так, ніби його атакують, хоча формально трафік може бути цілком "легальним".
Діагностика помилки HTTP 504
Найчастішою помилкою адміністраторів при появі коду HTTP 504 є паніка. Адміністратор починає крутити таймаути, перезапускати контейнери та переписувати конфігурації наосліп. Іноді це навіть допомагає, але, на жаль, або не надовго, або взагалі може призвести систему до більш масштабного збою.
Ми вже знаємо, що помилка 504 майже ніколи не вказує на джерело проблеми безпосередньо. Помилка з’являється в одному місці, а справжня причина може лежати взагалі в іншому шарі інфраструктури. Тому найважливішим завданням стає саме діагностика та локалізація проблеми.
Нижче ми навели базовий сценарій діагностики, який можна застосувати до більшості інфраструктур, оскільки всі сучасні додатки та системи будуються приблизно однаково і з використанням одних і тих самих складових.
Перевірка логів веб-сервера
Завжди варто починати діагностику з перегляду логів, і краще з логів reverse proxy, найчастіше це Nginx. Саме там зазвичай з'являється перша нормальна підказка, яка може вказати на справжню причину проблеми.
Для початку дивимося лог помилок:
tail -f /var/log/nginx/error.log
Дуже часто там з'являється щось на кшталт:
upstream timed out (110: Connection timed out)
Це вже чудова зачіпка, з якої ми бачимо, що Nginx не зміг дочекатися відповіді від backend.
Потім варто переглянути і access.log:
tail -f /var/log/nginx/access.log
Особливо цікавими для нас будуть поля на кшталт request_time та upstream_response_time. Якщо вони раптово починають зростати з мілісекунд до десятків секунд, то проблема майже напевно вже всередині backend або бази даних.
Іноді цього вистачає, щоб одразу зрозуміти напрямок пошуку. Особливо коли видно, що timeout виникає лише на конкретних URL або API-методах.
Звернення до backend безпосередньо
Наступним розумним кроком буде прибрати з ланцюжка proxy і перевірити саму програму безпосередньо. Тобто не через Nginx, Cloudflare або балансувальник, а відразу в backend. Це зручно робити за допомогою простого curl-запиту:
Наприклад:
curl http://127.0.0.1:8000
або:
curl http://backend_container:3000
Якщо безпосередньо backend відповідає швидко, а через proxy з'являється помилка 504, значить очевидно, що проблема десь між ними, наприклад timeout, мережа, налаштування proxy, CDN або балансувальник.
Якщо ж backend зависає навіть безпосередньо, тоді копати потрібно вже всередині додатка.
До речі, при роботі через Cloudflare є один нюанс. Іноді корисно тимчасово відключити proxy-режим і звернутися безпосередньо до origin-сервера. Це швидко показує, чи пов'язана проблема з CDN, чи сервер сам не справляється.
Перевірка стану backend
Якщо проблема все ж у самому backend-сервері, тоді будемо детальніше розбиратися саме з ним.
Неважливо, що ви використовуєте: Gunicorn, Node.js, PHP-FPM, uWSGI або Java-сервіси - логіка завжди приблизно однакова. Для початку потрібно зрозуміти, чи перевантажений сервер, тобто починаємо з перевірки буквально самого заліза.
Зазвичай починають з таких команд, як:
top
або:
htop
Дивитися нам потрібно ось на що: Як ми вже згадували вище - swap тут особливо показовий, оскільки якщо Linux почав активно вивантажувати пам'ять на диск, то продуктивність може критично просідати навіть без повного падіння сервера.
- load average;
- використання RAM;
- swap;
- I/O wait;
- кількість backend-процесів;
- завислі worker'и.
Перевірка бази даних
Оскільки практично жоден додаток або сайт не обходиться без бази даних, то варто перевірити і її, оскільки часто причиною проблеми може стати саме вона.
У PostgreSQL зазвичай насамперед дивляться:
SELECT * FROM pg_stat_activity;
Особливо підозріло виглядають:
- long-running queries;
- блокування;
idle in transaction;- важкі JOIN;
- sequential scan;
- величезний execution time.
Перевірка мережі
Ну і нарешті, іноді backend може бути повністю справним, як і база даних. А проблема полягає в мережі. Тому мережу ми теж завжди діагностуємо.
Для початку зазвичай перевіряють:
ping
traceroute
mtr
Потім вже дивляться на firewall rules, security groups, NAT, VPN, CDN routing, MTU. Так-так, MTU теж іноді псує життя адміністратора абсолютно абсурдним чином.
Як виправити помилку HTTP 504
Спосіб виправлення HTTP 504 завжди залежить від того, де саме була локалізована проблема. Іноді вистачає однієї правки в timeout, а іноді з'ясовується, що backend вже давно працює на межі, просто проблема нарешті стала помітною для користувачів.
На жаль, немає ніякої "чарівної пігулки", щоб "вилікувати" помилку 504, особливо якщо інфраструктура вже перевантажена. Тому давайте розглянемо кілька речей, які можуть бути корисними в цьому випадку.
Збільшення timeout
Перше, що зазвичай роблять при появі помилки 504 - це збільшення timeout.
Ну і іноді це дійсно виправдано, зокрема, якщо backend виконує важке, але коректне завдання, наприклад збирає великий Excel-звіт, генерує великий архів, рендерить відео або обчислює складну аналітику.
У Nginx зазвичай звертають увагу на ці інструкції у файлі конфігурації:
proxy_read_timeout 120;
proxy_connect_timeout 60;
proxy_send_timeout 120;
Для PHP-FPM:
request_terminate_timeout = 120
Але проблема в тому, що timeout дуже легко перетворити на палицю, про що ми говорили трохи вище.
Якщо backend вже задихається під навантаженням, то збільшення часу очікування просто змушує користувача дивитися на завантаження довше. Більше того, повільні запити продовжують тримати зайнятими worker’и, черга зростає, а сервер починає розсипатися ще швидше.
Тому збільшення timeout - це скоріше тимчасовий захід, який іноді може принести користь, але в багатьох випадках може зіграти злий жарт. Але принаймні про цю опцію варто знати.
Оптимізація backend
У реальних production-системах саме backend найчастіше виявляється головним джерелом 504, і причиною цього є спроба додатка виконати занадто багато важкої роботи всередині одного HTTP-запиту.
Прикладами таких робіт можуть слугувати класичні: І поки backend цим усім займається, worker залишається зайнятим, у результаті чого нові запити накопичуються в черзі. Ну і з часом timeout починає поширюватися по всій системі.
- генерація PDF або Excel;
- експорт великих таблиць;
- важкі SQL-запити;
- обробка зображень;
- синхронні виклики зовнішніх API.
У таких випадках зазвичай допомагає: Наприклад, замість генерації PDF прямо всередині запиту backend може просто створити завдання в черзі та відразу повернути користувачеві статус обробки. Документ сформується окремо, без блокування worker’ів.
- винесення важких завдань у чергу;
- Celery, RQ, BullMQ та подібні системи;
- оптимізація SQL;
- додавання індексів;
- кешування Redis;
- пагінація;
- зменшення кількості ORM-запитів;
- відмова від синхронних викликів API.
- тощо
Після таких змін додаток зазвичай починає працювати не тільки швидше, але й набагато стабільніше під навантаженням.
Масштабування інфраструктури
Іноді проблема все-таки полягає в ресурсах самого сервера. Особливо часто це трапляється на VPS, які місяцями працюють на межі виділених ресурсів, поки одного разу не приходить трохи більше трафіку, ніж зазвичай. Після цього починаються випадкові timeout’и, зависання SSH і дивні лаги у всій системі.
У таких випадках допомагає, (ваш кеп):Більше цю тему обговорювати не бачимо сенсу, оскільки тут все й так очевидно.
- додати CPU;
- збільшити RAM;
- перейти на NVMe;
- розподілити backend по декількох інстансах;
- встановити балансувальник навантаження.
Налаштування keepalive та лімітів з'єднань
Буває й так, що CPU вільний, база даних працює, а timeout все одно з'являється. У такому випадку причина може критися в мережевих з'єднаннях, коли, наприклад, backend не справляється з великою кількістю keepalive-сесій або Nginx впирається в ліміти worker_connections.
Зазвичай у цьому випадку перевіряють такі інструкції, як:
keepalive_timeout 65;
та:
worker_connections 4096;
Потім вже дивляться на системні ліміти:
ulimit -n
Якщо серверу не вистачає файлових дескрипторів, то нові підключення починають зависати абсолютно хаотично. Особливо неприємно це виглядає під час crawler storm або L7 DDoS, коли сервер начебто працює, але частина запитів раптово переходить у режим timeout.
Які метрики моніторити, щоб запобігти 504
До певного моменту ми вважали, що необхідність моніторингу систем зрозуміла всім і це аксіома. Адже в більшості випадків HTTP 504 не з'являється раптово і зазвичай перед цим система починає поступово деградувати. Але виявляється, що на практиці дуже багато проєктів нехтують моніторингом. Особливо цим страждають т.зв. "вайбкодери" у своїх "вайбкод-проєктах", які навіть не замислюються над цим питанням.
Запам'ятайте, моніторинг - це один з найважливіших інструментів для запобігання будь-яких проблем у системі, зокрема й HTTP 504 Gateway Timeout. Він дозволяє помітити проблему ще до того, як користувачі почнуть бачити помилки та повідомляти вам про це в тікетах або листах.
Для production-інфраструктури зазвичай моніторять такі показники:
| Що моніторити |
Чому це важливо |
Інструменти |
| CPU Load |
backend не встигає обробляти запити |
Prometheus, Netdata, Grafana |
| RAM та Swap |
нестача пам’яті різко уповільнює backend |
Netdata, node_exporter |
| Disk I/O |
база даних і backend очікують операції диска |
iostat, Prometheus |
| Request Latency |
зростає час відповіді застосунку |
Grafana, OpenTelemetry |
| SQL Query Time |
повільні запити гальмують backend |
PostgreSQL Exporter, pg_stat_activity |
| Active Connections |
сервер перевантажується з’єднаннями |
Nginx Exporter, Netstat |
| Error Rate |
backend починає частіше повертати помилки |
Sentry, Loki |
| Queue Size |
фонові задачі не встигають оброблятися |
Celery Exporter, BullMQ metrics |
У невеликих проєктах часто вистачає комбінації Netdata + Grafana, а в більш складних інфраструктурах зазвичай використовують Prometheus, Loki та OpenTelemetry. Але все це "на любителя", і конкретний стек, звичайно, залежить від ваших потреб, завдань та ваших особистих навичок як адміністратора.
FAQ: HTTP 504 Gateway Timeout
Чим відрізняється 504 від 502?
502 Bad Gateway означає, що backend повернув некоректну відповідь. А 504 Gateway Timeout - означає, що backend не встиг відповісти вчасно.
Чи може база даних викликати 504?
Так. Це одна з найпоширеніших причин, оскільки довгі SQL-запити та блокування швидко призводять до timeout backend.
Чи допомагає збільшення proxy_read_timeout?
Іноді - так, але якщо backend перевантажений, то це є лише тимчасовим заходом.
Чи може Cloudflare викликати 504?
Іноді, але частіше Cloudflare просто показує проблему origin-сервера.
Чому 504 з'являється під навантаженням?
Backend перестає встигати обробляти запити через брак CPU, RAM, повільний SQL або високий I/O wait.
Чи може Docker або Kubernetes викликати 504?
Так, може. І тут основними причинами є ingress timeout, перевантажений Pod, restart loop або завислий контейнер.
Висновок
HTTP 504 Gateway Timeout - це одна з тих помилок, які майже ніколи не виникають "просто так" . Зазвичай це вже наслідок глибшої проблеми, коли backend не справляється з навантаженням, база даних відповідає занадто повільно, мережа починає втрачати пакети, контейнери стикаються з обмеженнями ресурсів або додаток виконує занадто важкі операції безпосередньо всередині запиту.
І найнеприємніше, що місце появи помилки часто взагалі не збігається з її джерелом.
Часто користувач бачить сторінку Cloudflare, адміністратор спостерігає - timeout у Nginx, а backend пише WORKER TIMEOUT у лозі. А насправді проблема весь цей час може полягати в одному SQL-запиті, який раптово почав виконуватися по 20 секунд.
Через це діагностика помилки 504 майже завжди вимагає розглядати інфраструктуру в цілому.
У класичній production-інфраструктурі HTTP 504 рідко з'являється зовсім раптово і зазвичай перед цим вже починають блимати тривожні сигнали, такі як зростання latency, повільні відповіді SQL, збільшення load average тощо. Просто багато хто помічає проблему лише в той момент, коли користувачі вже бачать Gateway Timeout.
Тому якісний моніторинг та належна архітектура часто запобігають появі помилки 504 ще до того, як вона встигає потрапити до браузера.












