Containerization has long been a widespread and common practice among IT teams and administrators. Docker is used by startups, large companies, and small development teams alike. But with convenience comes responsibility, because a single configuration error or disk failure is enough to put a project at risk of a large-scale failure, and in some cases, complete destruction, as data can be lost, the service becomes unavailable, and recovery from such a failure becomes a long and laborious process.
To avoid this, backing up your Docker infrastructure should not be a one-time action, but part of the overall architecture. In this article, we will break down the key elements of such a system, figure out what exactly needs to be backed up, what tools to use, go over the mistakes that even experienced engineers make, and how to build a strategy that really works.
What you really need to back up in a Docker infrastructure
Before setting up any backup system, it is important to understand what exactly is valuable in a Docker environment. Many novice engineers mistakenly try to “back up a container.” But a container is just an executable process, and there is no point in saving processes. It is necessary to save the data and configurations that ensure the project's operability.
Below, we will analyze which elements of the Docker infrastructure should be backed up and why.
What are critical components?
To avoid wasting resources on copying unnecessary data, it is important to separate data by type and target value. Each element of the infrastructure has its own role. For example, the database ensures the preservation and integrity of information, media files are user content, and docker-compose.yml stores the project architecture.
The table below shows what really needs to be backed up and which tools are best suited for this.
| Data Type |
Should You Back Up? |
How to Back Up |
Comment |
| PostgreSQL, MySQL, MongoDB |
Yes |
pg_dump, mysqldump, mongodump |
Volume files should not be copied under write load |
| User-uploaded files |
Yes |
tar, rsync |
Usually the most valuable part of the project |
| Cache (Redis, Memcached) |
Usually no |
Snapshot or skip |
Cache is easy to regenerate |
| Dockerfile, Compose, env |
Yes |
Git |
This is the “recipe” of the service |
| Docker images |
Sometimes |
docker save |
Needed if there is no Dockerfile or the build is manual |
Why volumes should be at the center of any backup strategy
Docker volumes are state storage. A container can be destroyed and recreated, but the volume is actually its real content, since it is the volumes that store database files, user files, and other important artifacts. Therefore, any discussion of Docker infrastructure backup boils down to working with volumes.
To understand where a volume is physically located, you can use the following command:
docker volume inspect my_volume
And to archive it, use a simple tar command:
sudo tar -czf media_backup_$(date +%F).tar.gz /var/lib/docker/volumes/my_volume/_data
Volumes are the most important link that needs to be protected because they are what restore the viability of the project.
A realistic failure scenario
For a better understanding, imagine an online store where the database and media are stored on Docker volumes. If the MySQL container suddenly stops working, it's no big deal. You can quickly launch a new container with MySQL and specify the data storage location to quickly restore the service.
But if, for some reason, the /var/lib/mysql volume becomes unreadable, it means that orders, transactions, customer lists, and all other data critical to the project and the business as a whole will be lost. Without it, the project is effectively lost.
However, with a proper backup, restoring the volume and the entire service will only take a few minutes.
Basic strategies for backing up Docker data
There are several approaches to backup, and each of them solves its own problems. There is no universal option, as what is suitable for a small blog may not be suitable for a high-load system.
In this section, we will discuss the main strategies, their advantages, limitations, and application options.
Overview of backup approaches and their applicability
Before moving on to each method, it is worth looking at the big picture. The table below will help you understand which option is right for your project.
| Method |
Speed |
Reliability |
Complexity |
Where Used |
| tar archiving of volumes |
Medium |
Medium |
Low |
Low-cost VPS, medium-sized projects |
| Database dump |
High |
High |
Medium |
High-activity databases |
| VM snapshots |
Very high |
High |
Medium |
Proxmox, VMware, AWS |
| Cloud backup services |
High |
High |
Medium |
S3, Backblaze, Wasabi |
| Restic + rclone |
High |
Very high |
Medium |
CI/CD pipelines, DevOps environments |
| GitOps |
Instant |
Maximum |
Low |
All types of projects |
Now let's go through each point in more detail and analyze each approach separately.
1. Volume backup using tar
Volume archiving is one of the easiest ways to store data. It is suitable for small projects with a moderate amount of information and infrastructure deployed on a single host.
The advantage of this approach is its versatility, as tar will work anywhere there is access to the file system.
Example:
docker volume inspect project_data sudo tar -czf data_$(date +%F).tar.gz /var/lib/docker/volumes/project_data/_data
Limitations:
- does not ensure consistency when actively writing to the database;
- slow recovery for large volumes;
- not well suited for high-load systems.
2. Exporting database data using built-in tools
For serious projects, the preferred method is to back up data in the form of dumps. This method guarantees the consistency of table states, even when the database is under load.
This method uses special utilities provided by each DBMS, and their use makes data recovery more predictable, simple, and, most importantly, safe. Let's look at examples for different DBMSs.
PostgreSQL:
pg_dump -U user -F c -f backup.dump projectdb
MySQL:
mysqldump -u user -p database > dump.sql
MongoDB:
mongodump --out /backups/mongo_$(date +%F)
This approach is suitable for virtually all production systems, including those with active data growth.
3. Volume and virtual disk snapshots
Virtualization (Hyper-V, VMware, AWS EC2) allows you to take instant snapshots of the file system. This is a fast and reliable way to back up.
The main idea behind the snapshot approach is to “freeze” the state of the disks at a specific point in time. It is effective for large amounts of data, when a regular backup would take hours.
Snapshots are good if:
- the project runs on virtual machines;
- the data is actively changing;
- high recovery speed is important.
4. GitOps for configurations
Configurations are the basis of predictability. Without docker-compose.yml, Dockerfile, and environment variables, recovery loses its structure and turns into guessing parameters.
The GitOps approach assumes that:
- all configurations are stored in Git;
- the infrastructure is described declaratively;
- the server can be “recreated” from the repository.
This does not replace data backup, but complements it, making recovery fast and, importantly, repeatable.
How to build a competent Docker backup plan
Effective backup is not just about choosing tools. It is a process that must be regular, documented, and automated. In this section, we will look at the key elements of a work plan that can be used in any Docker infrastructure.
Identifying critical data
Every project has a unique value structure. For e-commerce, order tables are most important; for media services, it's uploaded files; for SaaS, it's user data. Identifying critical points is the basis of a backup plan.
Backup frequency
The backup frequency should match the data update frequency:
- high-load databases - several times per hour;
- CMS, blogs - once per day;
- large projects - incremental copies.
The right frequency reduces the load on the server and ensures that copies are up to date.
Geographical distribution of copies
Storing backup files on the same server as the working containers is a direct path to data loss.
Copies must be stored on a server in another data center, on S3, NAS, or a dedicated VPS.
Recovery testing
Every backup must be tested. Otherwise, it becomes nothing more than an illusion of security. Therefore, at least once a month, you should deploy a test environment and verify that the project can be restored completely and without errors.
Typical backup architecture for a Docker project
The working architecture usually looks like a chain of components. This helps to ensure control at every stage and automate the process.
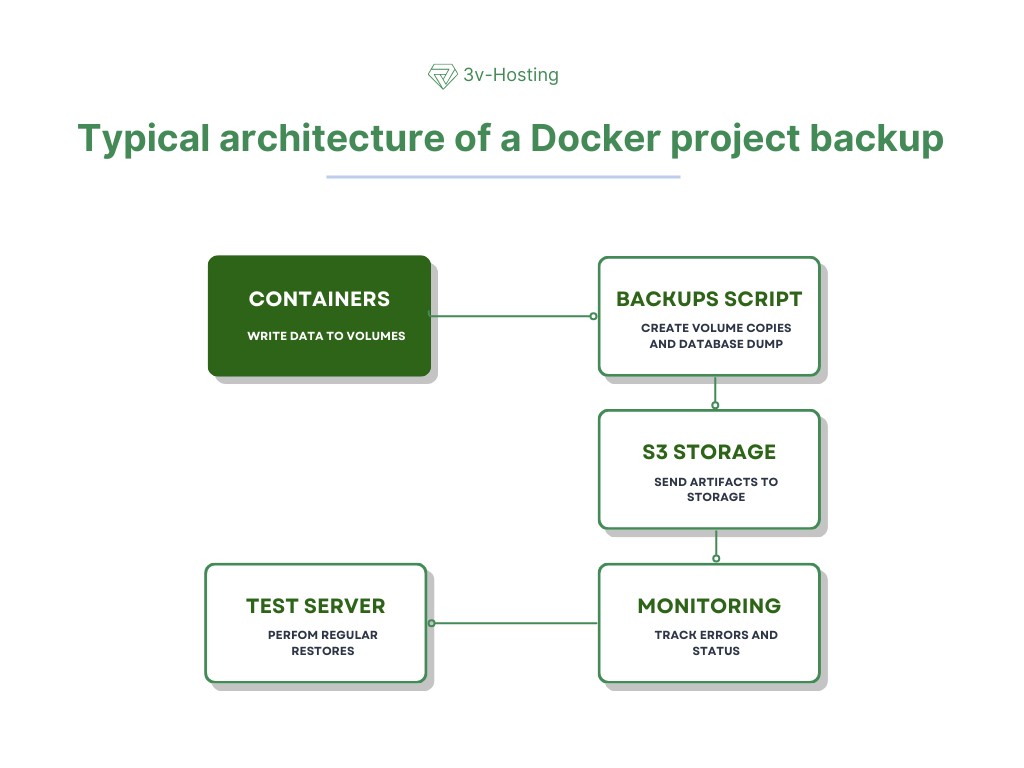
Containers write data to volumes.
Each service runs inside its own container, but all important data - databases, media files, caches - is stored in dedicated volumes. This ensures their independence from the container and makes subsequent backup possible.
The script creates copies of volumes and database dumps.
An automated script or utility runs on a schedule, sequentially dumping databases and archiving the necessary volumes. At this stage, full backup artifacts are formed.
The artifacts are sent to S3 or other storage.
The resulting files are uploaded to remote storage: S3 object storage, FTP, a separate server, or NAS. This protects data from loss in the event of a primary host failure.
Restores are performed regularly on a test server.
To ensure that the backups are actually working, they are periodically deployed on a separate test bench. This allows us to detect problems in advance that might only become apparent during a real recovery.
Monitoring tracks errors and execution status.
All backup processes are logged and sent to a monitoring system (e.g., Prometheus or Grafana). If the copy is not completed, interrupted, or fails, the team receives a notification and can respond quickly.
Mistakes even experienced engineers make
Even those who have been working with Docker for many years sometimes make mistakes that lead to data loss. This is partly because Docker often creates a false sense of security.
The main mistakes include:
- storing copies on the same disk;
- lack of database dumps;
- ignoring secrets;
- lack of backup logging;
- lack of backup versions;
- storing data without encryption.
Each of these mistakes is relatively easy to fix by incorporating backup into your DevOps processes.
Tools for automating backup
As the number of containers and data in your project increases, manual backup becomes cumbersome and inconvenient. Therefore, automation should be an essential part of your infrastructure. The following tools are convenient for automation:
Bash scripts
For small Docker hosts, regular bash scripts are sufficient. They allow you to fully control the process and are easily adaptable to any requirements.
Restic and rclone
Restic is a powerful tool that supports encryption, deduplication, and incremental backups. In conjunction with rclone, it is ideal for uploading data to S3 or Backblaze.
Velero
Although Velero is associated with Kubernetes, it is also used for Docker projects that require complex recovery logic.
Docker Compose Backups (DCP)
Ready-made utilities that can automatically create volume archives on a schedule.
Example of a backup scheme for a small project
Small projects (e.g., application + PostgreSQL + Nginx) can use a simple but effective backup structure.
Directories:
/backups/
├── db/
├── media/
├── configs/
└── logs/
The simplest algorithm:
- Execute pg_dump;
- Archive the media volume;
- Save configurations to Git;
- Send files to S3;
- Clean up old copies via logrotate.
This approach makes recovery fast and repeatable.
Multi-layered backup strategy
A reliable approach involves multiple levels of backup, each with its own purpose.
| Level |
Frequency |
Purpose |
| Hot backups |
Every 1–4 hours |
Fast recovery |
| Full backups |
Daily |
Protection from failures |
| Long-term backups |
Monthly |
Rollback to older states |
This scheme often helps protect against user errors, critical bugs, accidental deletions, and hardware failures.
FAQ on Docker backup
This section answers the most common questions that engineers and developers often have when setting up backup.
Do I need to stop containers for backup?
Only if you are copying the volume directly (tar, rsync) and the database is actively writing data at that moment. In such situations, the file structure may become inconsistent. If you are using pg_dump, mysqldump, or other standard DBMS tools, then you do not need to stop the containers.
Is it possible to back up databases without stopping the container?
Yes. Most modern databases support hot dumps, which are created without interrupting the application. This is a safe and standard backup method.
Which is faster for recovery, a dump or a volume copy?
It is usually faster and more reliable to restore a database from a dump because the DBMS correctly recreates the structure and data. A volume copy is only suitable if the database was stopped before the copy was created.
What to do with secrets?
It is better to store secrets separately from backups, in encrypted form or in secret repositories such as Vault or SOPS. This reduces the risk of key compromise.
Are incremental copies necessary?
Yes, if the amount of data is significant. Incremental backups reduce the load on the disk and shorten the time it takes to create copies.
Conclusions
A good backup strategy is not a luxury, but a necessity. Docker allows you to create flexible and scalable systems, but it is not the structure, but the data that makes your project valuable. And if you don't take care of their security, even the perfect architecture won't save you from the consequences of a failure.
An effective backup plan should include regularity, automation, geographic distribution, and recovery testing. Projects where backup is integrated into DevOps processes become resilient and can easily survive any incidents. We wish the same for you!












